Mettre en œuvre des principes de Data-Mesh pour mettre à l’échelle la couche de données de votre organisation
Publication originale :
Auteur:Assaf Liebstein
Le: 15 Novembre 2020
URL: https://medium.com/yotpoengineering/the-4-data-mesh-principles-to-create-a-data-oriented-rnd-6f2e291bcb5b
Temps de lecture : 6 min
Chez Yotpo, nous construisons une plate-forme pour servir les entreprises de commerce électronique qui comprend plusieurs produits, tels que: les évaluations et les évaluations, la fidélisation, les références, le marketing visuel et le marketing par SMS.
Travailler dans une organisation multi-domaines orientée microservices peut créer une architecture de type labyrinthe qui complique le développement de produits. Des sources de données omniprésentes sont constamment créées tout au long du travail de routine des ingénieurs.
Prenons l’exemple d’un développeur mettant en œuvre un rapport de synthèse d’utilisation sur les différentes lignes de produits. Il s’agit d’un cas d’utilisation classique pour l’implémentation d’un pipeline de données à agréger sur plusieurs sources.
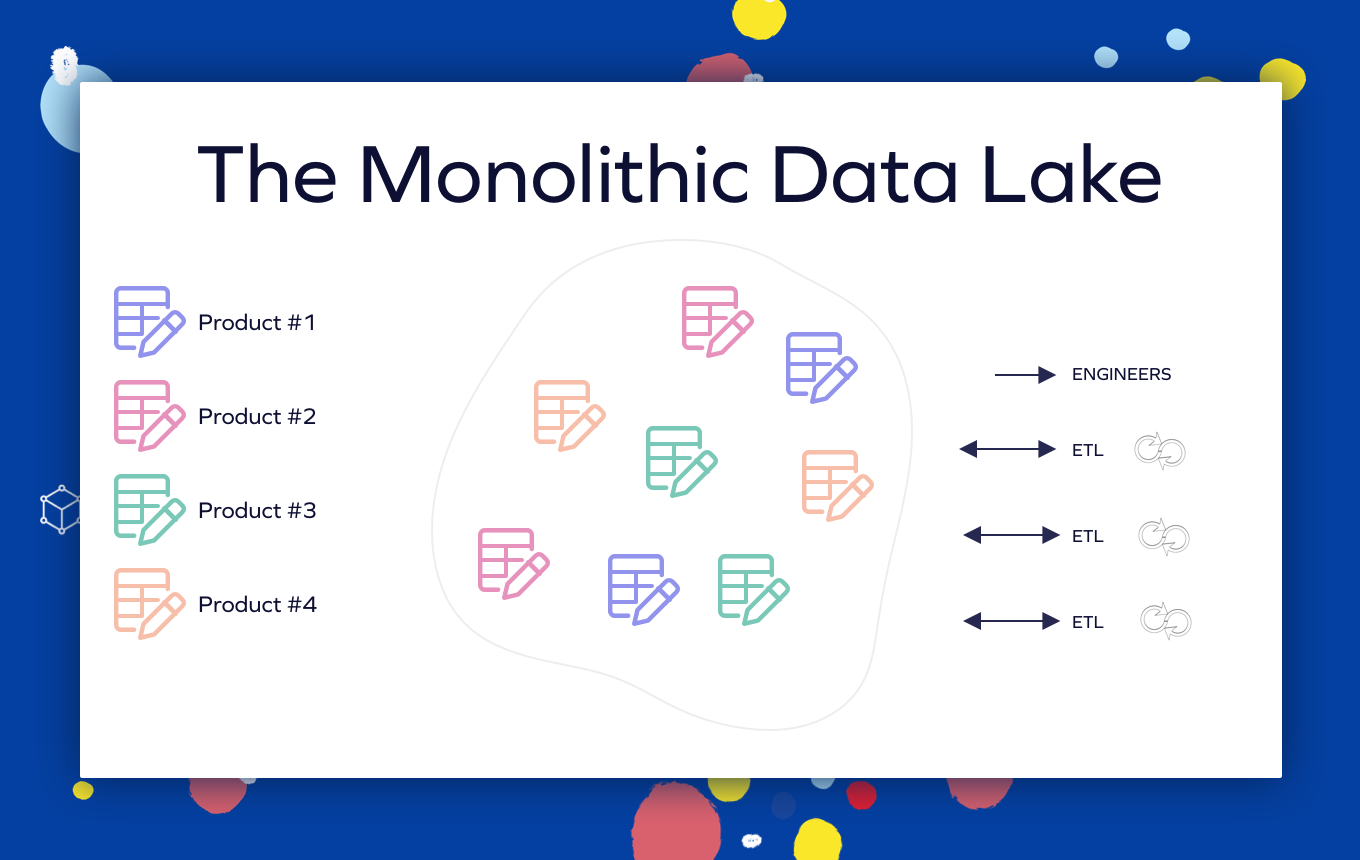
Il n’y a pas de propriété et de séparation de domaine claires entre les différents actifs. Les processus ETL et l’accès des ingénieurs à la plateforme sont gérés sans niveau de gouvernance.
Désormais, le développeur, qui n’est peut-être pas familier avec l’architecture des données de l’organisation, doit faire face à de nouveaux types de problèmes:
- Toutes les sources de données requises sont-elles disponibles ?
- Où est-il stocké ?
- Comment configurer le processus ETL pour qu’il s’exécute périodiquement ?
- Comment le monitorons-nous ?
Toutes ces lacunes peuvent entraîner une forte dépendance à l’égard de l’équipe d’ingénierie de la plate-forme de données, ce qui peut entraîner des retards de livraison, un manque de sentiment d’appartenance et une mauvaise qualité du produit en raison du manque de compréhension des données par l’ingénieur des données.
Il semble donc qu’il y ait un compromis: utiliser les pouvoirs des outils de données et dépendre d’une équipe externe cloisonnée d’experts en données, ou être complètement indépendant mais dépouillé des avantages de la plate-forme de données.
Pour résoudre ce dilemme, nous avons besoin d’un changement d’approche. Zhamak Deghani de ThoughtWorks a fourni le concept révolutionnaire de «Data Mesh», l’un des nouveaux principes fondamentaux de l’ingénierie des données dans la 3e décennie du 21e siècle.
L’idée de base de Data Mesh est de décentraliser l’approche monolithique des données reflétée par un seul lac de données / entrepôt de données et un seul groupe de données, en demandant aux équipes de développeurs de considérer les données comme un produit qu’elles servent à l’organisation.
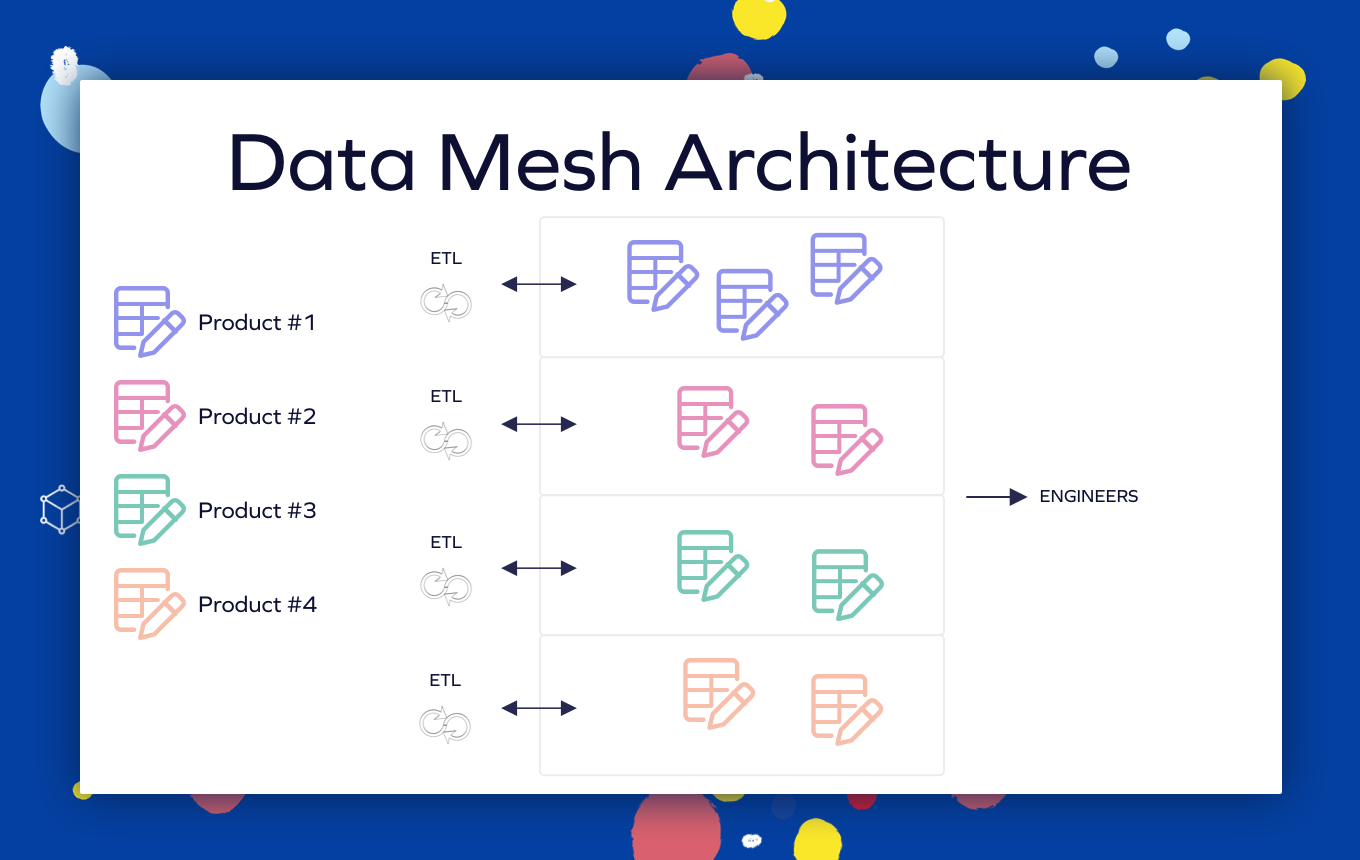
Il existe une séparation notable entre les sources de données et les pipelines des différents domaines. Les ingénieurs reçoivent une interface indépendante du domaine avec la plate-forme de données.
Si nous voulons transférer la propriété des pipelines de données et des actifs de données aux équipes de développement, nous devons leur donner les moyens d’utiliser les produits de données.
On peut prendre un exemple d’un autre domaine qui a récemment transféré la propriété d’une équipe spécialisée au développeur généraliste: DevOps, où la responsabilité de déployer un service en production s’est progressivement déplacée vers les développeurs généralistes et les SRE.
Dans cet article de blog, nous discuterons de certaines des pratiques que nous utilisons chez Yotpo pour fournir les outils de données en tant qu’infrastructure de données en libre-service, et de la façon dont nous avons qualifié les données de citoyens de premier ordre dans notre stock technologique.
Si vous êtes un ingénieur ou un chef de produit qui souhaite faire évoluer l’infrastructure de données de votre organisation, cet article de blog s’applique à vous.
Voici les principes clés sur lesquels repose une plateforme de données en libre-service / évolutive / distribuée:
1. Accessibilité
L’organisation multi-domaines génère de nombreuses sources de données. Certains d’entre eux peuvent être de nature similaire, comme la table Users table qui existe dans divers produits. L’architecture de données organisationnelle monolithique commune contredit l’architecture d’application distribuée commune. Nous créons généralement un seul lac de données, avec diverses sources de données organisées dans différents domaines. Cela peut créer la situation d’une expérience accablante et déroutante pour l’utilisateur de la plate-forme de données.
Le moyen le plus fondamental de résoudre ce problème consiste à utiliser un catalogue de données. Des outils, tels que AWS Glue Data Catalog ou le Hive Metastore open source, fournissent un mécanisme simple pour gérer les métadonnées des tables qui peuvent être perdues dans la structure hiérarchique du lac de données.
Les outils d’exploration de données, tels que Apache Atlas ou Lyft’s Amundsen, sont un autre ensemble d’outils très utiles. Ces outils fournissent un index des différentes tables, ajoutant la possibilité de catégoriser, documenter et suivre le data-lineage. Plus important encore, ils permettent la gouvernance des données, qui est une pratique obligatoire lors de la mise en place d’une infrastructure de données en libre-service. C’est également une étape obligatoire pour se conformer aux normes de confidentialité de l’industrie.
Chez Yotpo, nous utilisons Hive Metastore, qui s’intègre facilement à Spark, Airflow, EMR, Redshift et Databricks. Pour l’exploration et la gouvernance des données, nous utilisons Apache Atlas avec Apache Ranger.
2. Simplicité
Si nous voulons que nos développeurs puissent facilement posséder et maintenir les données de leur domaine, nous devons rendre l’utilisation des outils de données simple et indolore. Pour ce faire, nous présentons une solution simple pour chacun des éléments suivants:
Outils d’interrogation
Nous souhaitons que nos développeurs se familiarisent avec les données. Pour ce faire, nous devons proposer un moteur de requêtes évolutif, performant et simple d’utilisation qui sera accessible à tous les utilisateurs via l’IDE, l’intégration d’un client SQL ou toute autre interface simple.
Exécution
Nous devons nous assurer que les pipelines utilisent un outil ETL standard, simple à utiliser, adapté aux sources et aux cibles de l’organisation. L’outil ETL choisi doit être intuitif, fiable et intégratif avec toutes les sources de données critiques, afin qu’il soit bien adopté par les développeurs non-data.
Chez Yotpo, nous utilisons Metorikku, un développement open source interne. Metorikku généralise les travaux par lots et en continu Spark, à l’aide d’un simple fichier YAML descriptif avec des étapes SQL.
Planification et gestion des flux de travail
Il s’agit d’une partie inséparable de l’exécution des ETL. Pour permettre aux développeurs de gérer leurs jobs, nous devons proposer des générateurs pour générer des pipelines. Les générateurs doivent utiliser la pile de données standard et n’ont besoin que d’un petit ensemble de variables pour fonctionner.
Chez Yotpo, nous utilisons Apache Airflow pour planifier et gérer les pipelines de données. De plus, nous utilisons des générateurs personnalisés qui prennent en charge nos normes, de sorte que tout développeur, même celui qui n’a aucune expérience Python, puisse créer et gérer sans effort de nouveaux DAG.
Il est conseillé d’éviter une approche monolithique et de distribuer les pipelines physiquement ou logiquement en utilisant différents déploiements ou autorisations.

Photo de Trace Hudson sur Pexels
3. Fiabilité
La prochaine étape de l’évolution de l’ingénierie des données va de pair avec une infrastructure mature et robuste.
Pour mettre en œuvre avec succès l’architecture de maillage de données, nous devons établir des normes élevées pour ce qui suit:
Disponibilité
Les données brutes et matérialisées doivent toujours être disponibles. Une seule table peut être utilisée dans plusieurs pipelines qui dépendent tous de sa disponibilité. Historiquement, la disponibilité est gérée avec une combinaison de versions de table immuables et de catalogue de données. L’approche la plus moderne consiste à gérer les mises à jour à l’aide d’ ACID événements.
Nous utilisons Apache Hudi pour gérer et mettre à jour nos parquets Data Lake.
Freshness
L’une des avancées majeures de ces dernières années est l’utilisation de processus de données en temps réel, suivis de frameworks, tels que Apache Flink et Spark en streaming structuré. Une architecture distribuée nécessite une persistance élevée des données sur plusieurs domaines.
Nous avons poussé en avant le principe de création d’un lac de données sans latence à l’ aide de Change Data Capture et Apache Hudi.
Stabilité
Les infrastructures modernes dépendent fortement des courtiers de messages, tels que Kafka, ou des plates-formes d’orchestration, telles que K8S. Nous devons être certains que ces infrastructures sont suffisamment matures et stables en tant qu’infrastructure partagée. Il est important de prendre en charge la mise à l’échelle automatique, les procédures de reprise après sinistre et la présentation d’une surveillance prête à l’emploi.
4. Valeur
Afin de créer le changement de paradigme, nous devons inciter nos développeurs à adopter les outils de données. Cela créera inévitablement plus de données spécifiques au domaine dans le maillage de données et habituera les développeurs aux normes de qualité des données.
Prenons par exemple notre implémentation de Change Data Capture (CDC) en utilisant Debezium.
L’activation de CDC sur différentes bases de données de microservices permet de créer des flux de travail distribués complexes, sans avoir à écrire des producteurs PubSub fastidieux et répétables.
Après avoir intégré CDC dans notre infrastructure, nous avons compris la forte demande que nous avons dans notre R&D. Cela seul a naturellement exposé nos développeurs à un monde de produits de données.
Le développement et l’intégration de ces types de solutions est l’un des meilleurs moyens de motiver les ingénieurs logiciels à adapter leur pile aux outils de données.
Conclusion
Construire une plate-forme de données est un voyage, avec de nombreux jalons en cours de route. La plate-forme évolue constamment, les cas d’utilisation changent et le besoin constant de résister à l’échelle et à la complexité ne cesse d’augmenter. Le respect de ces directives vous assurera de suivre la bonne voie, quelle que soit la tendance technologique actuelle.

