
On vous propose une série d’articles pour revenir sur quelques algorithmes les plus souvent utilisés chez nos clients. On commence par l’un des algorithmes les plus simples : l’arbre de décision.
Un arbre de décision permet de construire des règles explicites et métiers à partir de vos données en fonction d’une variable cible que vous cherchez à expliquer. S’il est rarement utilisé tel quel en machine learning, c’est un outil élémentaire et indispensable qu’il vous faut maîtriser pour comprendre les algorithmes que l’on verra ensemble par la suite : le random forest (Algorithme N°2) et l’isolation forest (Algorithme N°3).
Principe de fonctionnement
Un arbre de décision permet d’expliquer une variable cible à partir d’autres variables dites explicatives.
Du point de vue mathématique : soit une matrice X avec m observations et n variables, associée à un vecteur Y à expliquer : il faut trouver une relation entre X et Y.
Pour ce faire, l’algorithme va chercher à partitionner les individus en groupes d’individus les plus similaires possibles du point de vue de la variable à prédire.
Le résultat de l’algorithme produit un arbre qui révèle des relations hiérarchiques entre les variables. Il est ainsi possible de rapidement comprendre des règles métiers expliquant votre variable cible.
Construction des règles
L’arbre de décision est un algorithme itératif qui, à chaque itération, va séparer les individus en k groupes (généralement k=2 et on parle d’arbre binaire) pour expliquer la variable cible.
La première division (on parle aussi de split) est obtenue en choisissant la variable explicative qui permet la meilleure séparation des individus. Cette division donne des sous-populations correspondant au premier nœud de l’arbre.
Le processus de split est ensuite répété plusieurs fois pour chaque sous-population (noeuds précédemment calculés) jusqu’à ce que le processus de séparation s’arrête.
Quelle est votre chance d’acceptation d’un crédit à la banque ?
Le schéma ci-dessous permet de comprendre la probabilité d’acceptation d’un crédit bancaire. Il s’agit d’un exemple fictif pour comprendre le principe de lecture d’un arbre de décision. Imaginez, le gérant d’une grande banque veut connaître ses propres règles d’acceptation ou non d’un crédit bancaire en fonction du profil des clients. Pour ce faire, il emploie un conseiller chargé de poser des questions à ces clients. Ce conseiller, un peu statisticien dans l’âme, fait la synthèse des résultats à son gérant en proposant l’arbre de décision qui suit.
Quelques explications… A la racine de l’arbre, 2 201 dossiers clients à l’étude.
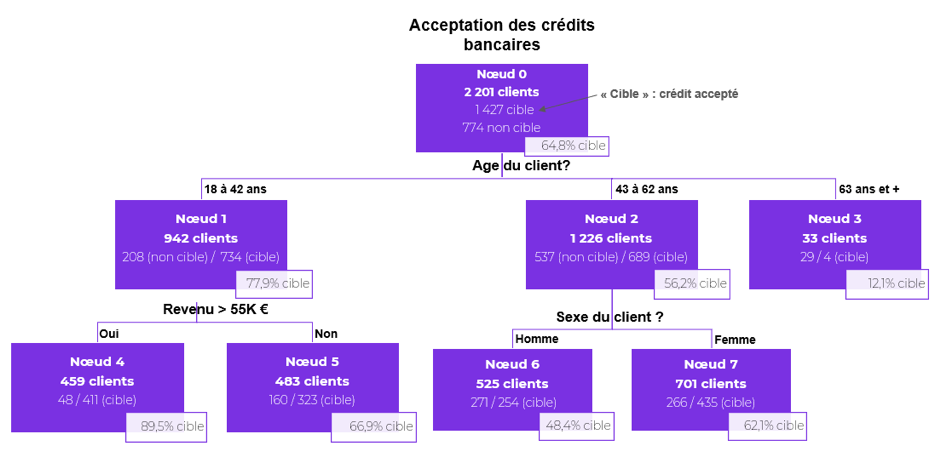
Parmi ces dossiers, 1427 seront acceptés (soit 64,8%) et 774 seront refusés (soit 35,2%). La variable explicative qui sépare le mieux les dossiers acceptés (notre variable cible) des autres dossiers est l’âge du client. Ainsi, chez 942 clients âgés entre 18 et 42 ans (42,8% de la totalité des clients), le taux d’acceptation de crédit atteint 77,9% (soit 734 clients) alors que chez les 33 clients âgés de 63 ans et +, le taux d’acceptation de crédit n’est que de 12,1%. La meilleure séparation de la population des clients âgés entre 18 et 42 ans (Nœud 1) se fait en fonction du revenu. Vous le voyez, les 459 clients ayant un revenu net annuel supérieur à 55K euros ont un taux d’acceptation de crédit de 89,5%.
Chez les clients âgés entre 43 ans et 62 ans, c’est le sexe qui est la variable la plus explicative de l’acceptation d’un crédit. Ainsi, chez les femmes, le taux d’acceptation d’un crédit est de 62,1% contre 48,4% pour les hommes de cette même tranche d’âge.
Limites de l’algorithme
Les arbres de décision peuvent mener au sur-apprentissage. Cela signifie que l’algorithme a trouvé une règle qui semble parfaite pour comprendre et décrire les données. Hélas, cette règle ne peut pas être généralisée. Pire encore, dans certain cas, il est possible que la règle trouvée change radicalement si vous introduisez quelques observations supplémentaires dans vos données initiales.
Pour aller plus loin
Il y a quelques questions clés à vous poser lors de la construction d’un arbre de décision.
- Quelles variables explicatives d’entrée choisir pour construire votre arbre ? Vous voulez expliquer une variable cible en fonction d’autres variables. Réfléchissez pour trouver un processus causal dans vos données (existe-il une relation de causes à effets entre différentes variables de vos données ?).
- Comment traiter des données continues (Exemple : la taille d’un individu, le prix d’un bien immobilier, …) et des données qualitatives (Exemple : la catégorie socio-professionnelle, …) ? Il faut pré-traiter vos variables et choisir le modèle d’arbre de décision qui convient le mieux.
- Comment définir la taille optimale d’un arbre ? Il faut penser à élaguer votre arbre (le couper à une certaine hauteur). En effet, un arbre trop profond (c’est-à-dire avec énormément de noeuds) est toujours synonyme de sur-apprentissage.
Pour continuer de répondre à ces questions, documentez-vous plutôt sur les trois algorithmes de la famille des arbres de décision : l’algorithme CHAID, CART et C4.5.
Conclusion
Si vous avez bien compris le fonctionnement de ce premier algorithme, vous comprendrez facilement les méthodes ensemblistes qui mettent en concurrence plusieurs arbres notamment le random forest (Algorithme N°2) et l’isolation forest (Algorithme N°3).

