
Les modèles de machine learning (ML) sont de plus en plus complexes. En effet, un modèle sophistiqué (de boosting XGBoost ou de deep learning) permet généralement d’aboutir à des prédictions plus précises qu’un modèle simple (de régression linéaire ou arbre de décision).
Il existe ainsi un compromis entre la performance d’un modèle et son interprétabilité : ce qu’un modèle gagne en performance, il le perd en interprétabilité (en inversement).
Que signifie exactement l’interprétabilité d’un modèle ?
L’interprétabilité se définit comme la capacité pour un humain à comprendre les raisons d’une décision d’un modèle. Ce critère est devenu prépondérant pour de nombreuses raisons.
Au niveau scientifique, le développement des connaissances et le progrès reposent sur la compréhension profonde du phénomène étudié. Il est donc inimaginable pour un data scientist de laisser fonctionner un modèle de machine learning sans chercher à connaître les variables influentes, sans chercher à vérifier la cohérence des résultats à la lumière des connaissances métier du domaine, … Il s’agit de comprendre, d’avoir confiance et d’avoir une preuve de la consistance du modèle.
Au niveau éthique : imaginons une situation dans laquelle un individu est atteint d’un cancer. Il se voit refuser son intervention chirurgicale à cause de la seule décision d’un algorithme. De plus, par nature cet algorithme sera complexe et alors aucun chirurgien ne sera en capacité de justifier une telle décision. Cette situation n’est pas acceptable.
Au niveau législatif : l’article 22 de la RGPD (Règlement Général sur la Protection des Données) prévoit qu’une personne ne doit pas faire l’objet d’une décision fondée exclusivement sur un traitement automatisé et émanant uniquement de la décision d’une machine.
Dans cet article, nous proposons de vous présenter deux méthodes d’interprétation de modèles de Machine Learning : les algorithmes LIME et SHAP. Ces deux méthodes fonctionnent en sortie d’un modèle complexe, boîte noire dont on comprend mal le fonctionnement.
Avant d’aborder les spécificités de chaque algorithme, nous vous proposons de parcourir rapidement ce qui caractérise les principales méthodes d’interprétabilité.
Les méthodes d’interprétabilité
Les différentes approches d’interprétabilité peuvent être définies selon les typologies suivantes :
– Méthodes d’interprétation agnostique versus spécifique : Les méthodes agnostiques s’utilisent pour n’importe quel type de modèles. Au contraire, les modèles spécifiques ne peuvent être utilisés que pour interpréter une famille spécifique d’algorithmes.
– Méthodes intrinsèques Versus méthodes post-hoc : Pour les méthodes intrinsèques, l’interprétabilité est directement liée à la simplicité du modèle alors que pour les méthodes post-hoc, le modèle n’est pas interprétable parce que d’emblée trop complexe.
– Méthodes locales versus globales : Les méthodes locales donnent une interprétation pour un seul ou un petit nombre d’observations. Au contraire, les méthodes d’interprétation globales permettent d’expliquer toutes les observations en même temps, globalement.
– Méthodes dites a priori versus a posteriori : Les approches a priori sont employées sans hypothèse sur les données et avant la création du modèle. Au contraire, les approches a posteriori sont employées après la création du modèle.
L’état de l’art actuel autour de l’interprétabilité des modèles de machine learning montre qu’il y a une volonté forte de mixer les différentes méthodes : {intrinsèques & globales} ou {post hoc & globales & agnostiques} ou encore {post-hoc & locales & agnostiques}.
LIME
L’algorithme LIME (en anglais, Local Interpretable Model-agnostic Explanations) est un modèle local qui cherche à expliquer la prédiction d’un individu par analyse de son voisinage.
LIME a la particularité d’être un modèle :
– Interprétable. Il fournit une compréhension qualitative entre les variables d’entrée et la réponse. Les relations entrées-sortie sont faciles à comprendre.
– Simple localement. Le modèle est globalement complexe, il faut alors chercher des réponses localement plus simples.
– Agnostique. Il est capable d’expliquer n’importe quel modèle de machine learning.
Pour ce faire :
– 1ère étape : l’algorithme LIME génère des nouvelles données, dans un voisinage proche de l’individu à expliquer.
– 2ème étape : LIME entraîne un modèle transparent sur les prédictions du modèle « boîte noire » complexe qu’on cherche à interpréter. Il apprend ainsi à l’aide d’un modèle simple et donc interprétable (par exemple, une régression linéaire ou un arbre de décision).
Le modèle transparent joue donc le rôle de modèle de substitut pour interpréter les résultats du modèle complexe d’origine.
Le principal inconvénient de la méthode LIME est lié à son fonctionnement local. Et, LIME ne permet pas de généraliser l’interprétabilité issue du modèle local à un niveau plus global.
Cas d’application avec Python
Avec Python, il existe une librairie lime. Selon le type de données d’entrée, vous pouvez utiliser :
– lime.lime_tabular pour des tables de données
– lime.lime_image pour une base de données d’images
– lime.lime_text pour un corpus de textes
Notre cas d’usage : expliquer le score de churn d’un client particulier, à partir de ses données transactionnelles. Différentes questions sont à se poser : Comment expliquer différentes classes de scores ? Qu’est-ce qui différencie le score de ce client par rapport aux autres clients? Quel comportement fait que ce client en particulier à un certain score ?
LIME nous a permis d’expliquer la prédiction d’un modèle de machine learning complexe de boosting XGBoost.
|
import lime.lime_tabular classifier_lime = lime.lime_tabular.LimeTabularExplainer(train_data_X.values, mode=’regression‘, training_labels=train_data_y, feature_names= data_dataset.feature_names, categorical_features=[‘CHAS‘]) lime_results = classifier_lime.explain_instance(test_data_X.values[0], sklearn_regressor.predict)
lime_results.show_in_notebook() |
Résultats :
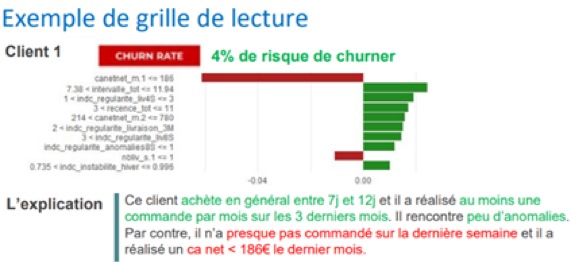
La différence de couleur nous montre tout d’abord quels sont les facteurs favorables et défavorables pour l’interprétation du churn :
– en vert : les facteurs favorables contribuent à augmenter la valeur prédite.
Dans notre exemple, les achats de notre client sont réguliers. Il n’y a aucune anomalie chez ce client.
– en rouge : les facteurs défavorables participent à augmenter le risque de churn d’un client.
Dans notre exemple, le client n’a presque rien acheté sur la dernière semaine. C’est un signal qui doit alerter : ce client peut être en train de se désintéresser de l’enseigne. De plus, sa valeur vie sur le dernier mois est faible (186€) au regard de ses achats passés. Il faut trouver un moyen de le réengager.
SHAP
La mise en œuvre de SHAP repose sur une méthode d’estimation des valeurs de Shapley. Il existe différentes méthodes d’estimation comme le KernelSHAP (méthode inspirée de LIME) ou le TreeSHAP (méthode à base d’arbres de décision).
Principe d’estimation des valeurs de Shapley
Pour un individu donné, la valeur de Shapley d’une variable (ou de plusieurs variables) est sa contribution à la différence entre la valeur prédite par le modèle et la moyenne des prédictions de tous les individus.
Pour ce faire :
– 1ère étape de calcul des valeurs de Shapley pour un individu en particulier : simuler différentes combinaisons de valeurs pour les variables d’entrée
– 2ème étape : Pour chaque combinaison, calculer la différence entre la valeur prédite et la moyenne des prédictions. La valeur de Shapley d’une variable correspond alors à la moyenne de la contribution de sa valeur en fonction des différentes combinaisons.
Illustrons simplement les choses
Imaginez que nous ayons construit un modèle de prédiction des prix des appartements à Paris. Pour une observation donnée, le modèle prédit la classe « Prix > 12 500€ /m2 » avec un score de 70% lorsque l’appartement dispose d’un balcon (variable presence_balcon = 1). Si lorsque l’on modifie la valeur balcon a 0 (absence de balcon) et que le score baisse de 20%, alors la contribution de la valeur balcon = 1 était de 20%.
Dans la pratique, les choses sont évidemment plus compliquées parce que pour obtenir une estimation correcte des valeurs de Shapley, il faudrait combiner toutes les valeurs que prend chaque variable du modèle sur l’ensemble de nos données. Le temps de calcul pourrait alors devenir extrêmement important.
Quelques lignes de code en Python pour tester SHAP
Avec Python, ce sont les librairies alibi et shap qui implémentent les méthodes d’estimation des valeurs de Shapley KernelSHAP, TreeSHAP (pour des cas d’usage à partir de données tabulaires) et DeepSHAP (pour des cas d’usage en deep learning).
|
import shap classifier_shap = shap.KernelExplainer(sklearn_regressor.predict, data_train_X) shap_results = classifier_shap.shap_values(data_test_X.iloc[0]) shap.waterfall_plot(classifier_shap.expected_value,shap_values,data_test_X.iloc[0]) |
Conclusion
Il est important de trouver un juste compromis en machine learning entre un modèle performant versus un modèle interprétable.
Avec LIME ou SHAP, vous pouvez rendre interprétable un modèle complexe à l’origine et ainsi favoriser son adoption auprès des métiers. Si comprendre un modèle est un impératif dans toute démarche scientifique, les contraintes juridiques imposent désormais de ne pas prendre une décision basée uniquement sur le résultat d’un algorithme automatique.
Retenez que l’algorithme SHAP, à l’heure actuelle, répond aux exigences normatives imposées par la RGPD.
Si vous êtes intéressé par ce sujet, nous vous invitons à vous documenter sur d’autres méthodes d’interprétabilité des modèles de machine learning telles que : les techniques reposant sur l’analyse de « graphiques ICE et PDP », les méthodes dites de « Permutation Feature Importance », les « explications contrefactuelles » ou encore les « ancres ».

