
Malgré l’incomparable potentiel business des modèles prédictifs, les percées de la Data Science restent encore balbutiantes dans la plupart des entreprises. Retour sur les raisons d’une adoption encore trop timide qui ouvre la voie à l’Analytics Augmenté comme vecteur d’accélération efficace.
Des business et de la data…
Petit Flashback. Au cours des années 90, la BI traditionnelle inaugure l’entrée de la culture de la donnée dans le monde de l’entreprise, selon trois promesses :
- constituer une base de connaissances sur les activités de l’entreprise,
- rendre la donnée disponible pour chaque entité de l’organisation en la stockant et l’historisant à l’aide de Data Warehouses et de Datamarts,
- adresser des cas d’usage concrets à des fins stratégiques par l’exploration, la modélisation et la restitution des données.
Cependant, à la suite de cette démocratisation de l’accès aux données, émerge rapidement un besoin de gagner en souplesse dans l’analyse et la représentation de cette information. Mais cette nécessité se heurte aux limites de la BI traditionnelle, qui ne permet que partiellement d’autonomiser les métiers en raison de contraintes diverses. Parmi les obstacles les plus courants à une démocratisation complète, on peut signaler :
- la centralisation des développements au sein de la DSI est source de frustration pour les métiers quant à leur capacité d’explorer leurs propres données, sans parler des délais trop importants d’évolution des applications en production (et l’absence de développement ou d’adaptation sur-mesure),
- les limites technologiques intrinsèques des systèmes non pensés pour de très grands volumes de données (Big Data) entraînent des problèmes de performance sur toute la chaîne de traitement de la donnée, sinon à des coûts prohibitifs
- l’approche conceptuelle des premières solutions, ne permettant pas d’analyser et corréler toutes les données potentielles de l’entreprise (ce qui a pour effet de freiner la découverte de nouveaux insights et donc consécutivement la dynamique d’innovation de l’organisation).
Un premier élan de démocratisation avec l’Analytics.
Ce manque est en partie comblé par l’apparition de nouveaux acteurs dès les années 2000 (Power BI, Tableau, Qlik Sense, Looker, Google Data Studio, ThoughtSpot, Sisense, …) proposant une approche Self-service BI avec ses nombreuses possibilités (Data Visualisation, Smart Analytics, Storytelling), sans oublier l’accent mis sur l’expérience utilisateur.
Ainsi, positionnée à mi-parcours de la chaîne de valeur data entre l’intégration de données et la Data Science, cette nouvelle spécialisation dite « Analytics » s’attelle à l’exploration et l’exploitation visuelle des données pour en extraire les indicateurs de performance (ou KPIs) pertinents et en donner une analyse rétrospective.
En parallèle de cette percée de l’Analytics, la Data Science (discipline scientifique prenant le relais du Data Mining) s’oriente elle, vers l’analyse prédictive, de sorte à tracer les hypothèses de réalisation future d’un événement. Mais malgré son immense potentiel de bénéfices pour l’entreprise, cette discipline peine quelque peu encore à se démocratiser.
Les challenges d’adoption de la Data Science et du Machine Learning.
En effet, l’industrialisation de la Data Science n’est pas un long fleuve tranquille… prédire ce qui va se passer sur un jeu de données parfaitement calibré dans le cadre d’un POC est une chose… mais c’en est une autre de parvenir à ce qu’un système de recommandation intelligent s’adapte à l’écosystème IT de l’entreprise et se convertisse en insights à haute valeur ajoutée pour les métiers (enrichissement des bases de données, connections avec le CRM, …) Et comment permettre à l’utilisateur final d’avoir confiance dans l’ensemble du processus de génération de la donnée ? En clair, comment bien réussir la mise en production ?
Des solutions de Machine Learning automatisées (Dataiku, DataRobot, Domino Data Lab) ont certes permis des progrès dans le déploiement de la Data Science en entreprise, mais encore faut-il sortir de l’effet « boîte noire » qui reste problématique et constitue un frein à l’adoption.
A n’en pas douter, la bonne solution pour favoriser et généraliser l‘adoption de la Data Science vient d’un juste compromis. En opérant le mariage best of breed (en ne retenant que les avantages de chacune des deux approches) de l’Analytics et de la Data Science, on crée les conditions d’une adoption aisée et on aboutit à ce que l’on appelle « l’Analytics Augmenté ». Voyons de plus près comment opérer ce rapprochement.
L’approche Augmented Analytics.
Comme illustré dans le graphe d’analyse comparative ci-dessous, certaines des applications finales des outils d’Analytics, telles que les dispositions en termes de vulgarisation, l’activation, la définition des KPIs métiers ou la visualisation des résultats, se révèlent d’une redoutable efficacité. Ces fonctionnalités les plus efficaces se présentent aujourd’hui comme une opportunité pour combler les manques de la Data Science et comme une solution prometteuse pour booster l’adoption de la discipline.
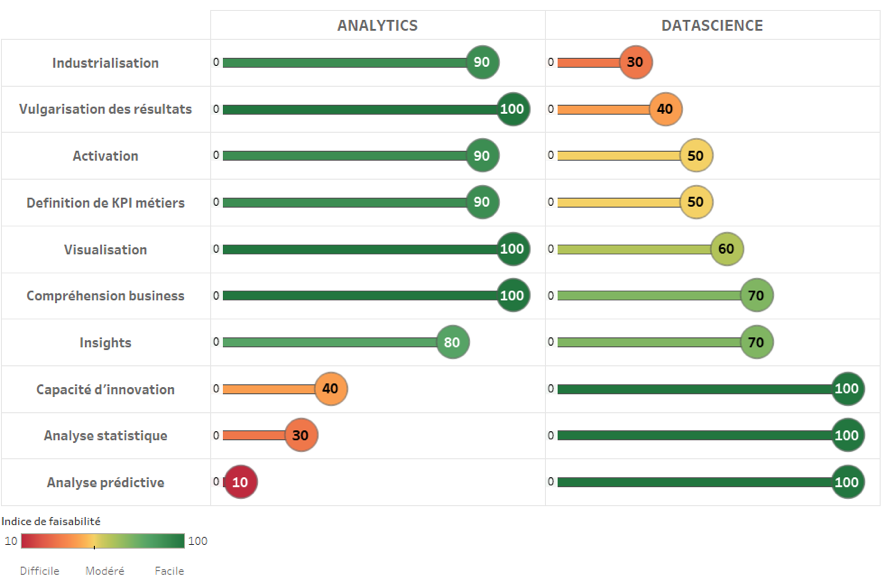
Analyse comparative des forces et faiblesses de l’Analytics et de la Data Science.
Concrètement aujourd’hui, les solutions d’Analytics intègrent des fonctionnalités que les Data Scientist s’approprient de plus en plus. Ainsi, par exemple, bien que le volet « Analyse » de Tableau propose par défaut l’algorithme k-means avec distances euclidiennes, un utilisateur averti pourra définir une approche différente (distances Manhattan par exemple).
L’utilisateur a aussi la possibilité de créer un paramètre ce qui permet de visualiser directement les impacts en termes de regroupement selon le nombre de clusters recherchés (paramètre « Nb Clusters ») et de combiner le tout dans une interface plus interactive au profit de ses interlocuteurs.

Possible programmation en R ou Python directement depuis Tableau.
Le rapprochement des deux disciplines se matérialise par l’apparition d’un nouveau profil : le Citizen Data Scientist, dont les travaux permettent d’aboutir à une vue claire et pertinente de l’information sur des thématiques plus avancées que celles d’un Data Analyst (analyses de corrélations, conceptions d’algorithmes, ...)
Prévisions dynamiques programmées en Python et self-service BI.
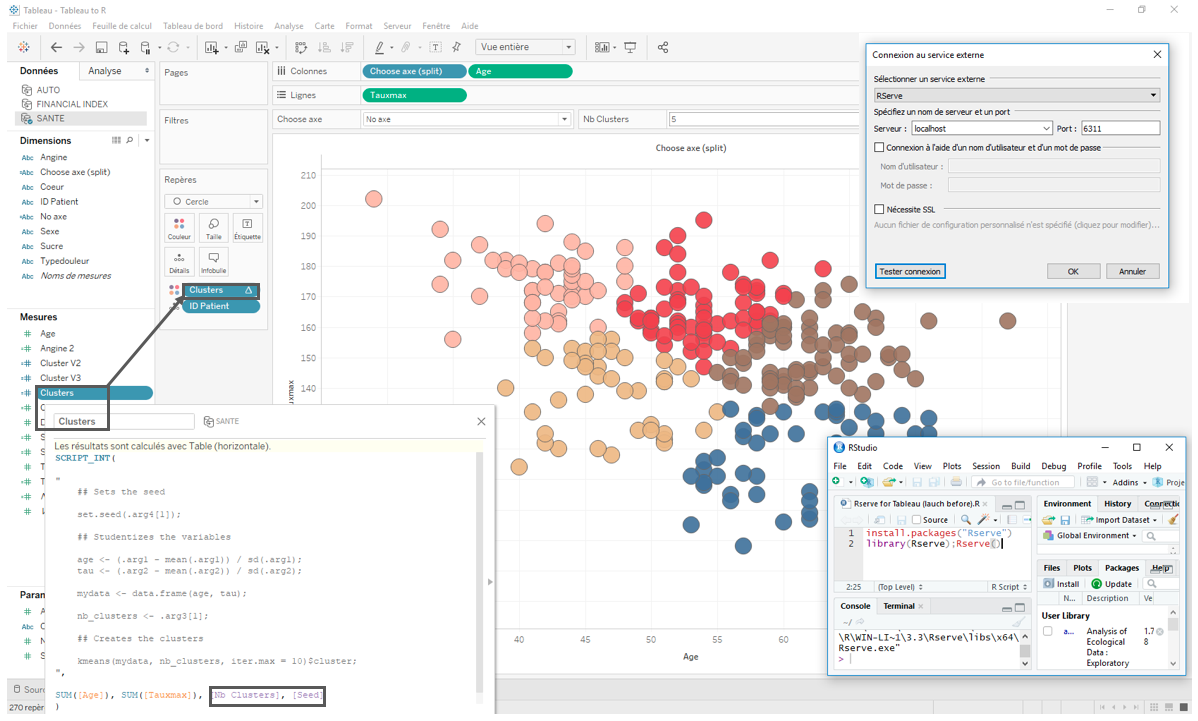
Intégration du langage R dans un champ calculé Tableau pour réaliser un clustering des individus d’une base de données.
Pour illustrer le propos, voici un exemple de visualisation des prévisions de faillite d’entreprises selon une approche LSTM (Long Short-Term Memory Recurrent Neural Network) programmée en Python et dont les outputs sont réutilisés dynamiquement dans Tableau.
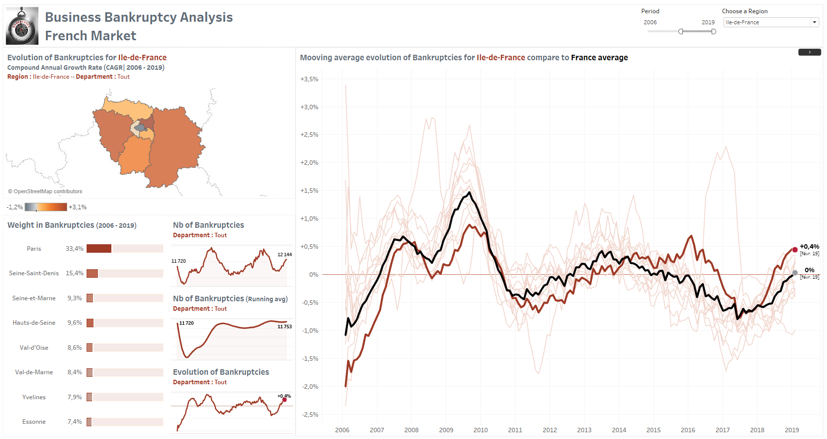
Application interactive où il est possible d’analyser le nombre de faillites d’entreprises et son évolution selon un niveau de détail Période/Région/Département.
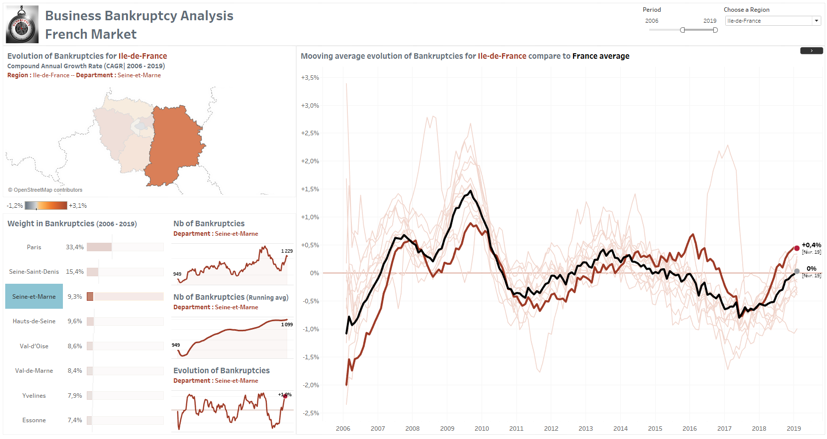
Focus sur la Seine-et-Marne qui pèse 9,3% des faillites enregistrées en Île de France sur la période allant de 2006 à 2019.
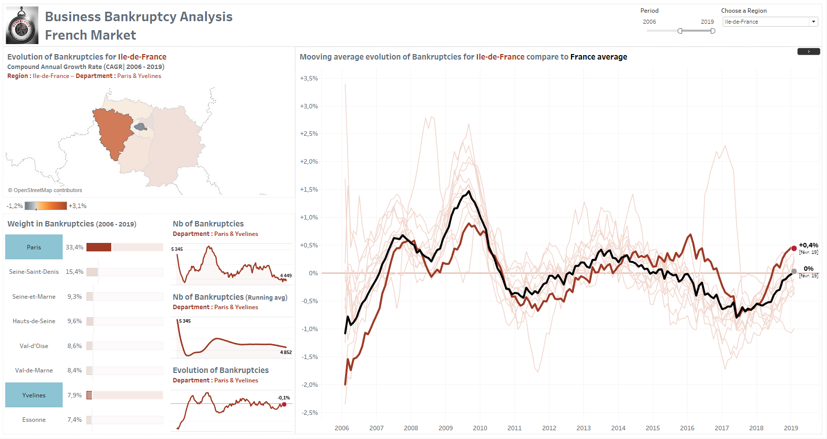
Double sélection sur les Yvelines et Paris qui pèsent respectivement 33,4% et 7,9% des faillites enregistrées en l’Île de France sur la période allant de 2006 à 2019.
La capacité à relier les sorties de prévisions Python à Tableau de façon dynamique permet de représenter ces dernières d’une manière plus intelligible qu’auparavant. Cette nouvelle fonctionnalité se présente par conséquent comme une aubaine pour la démocratisation de la Data Science.
Dans le détail comment cela fonctionne-t-il ?
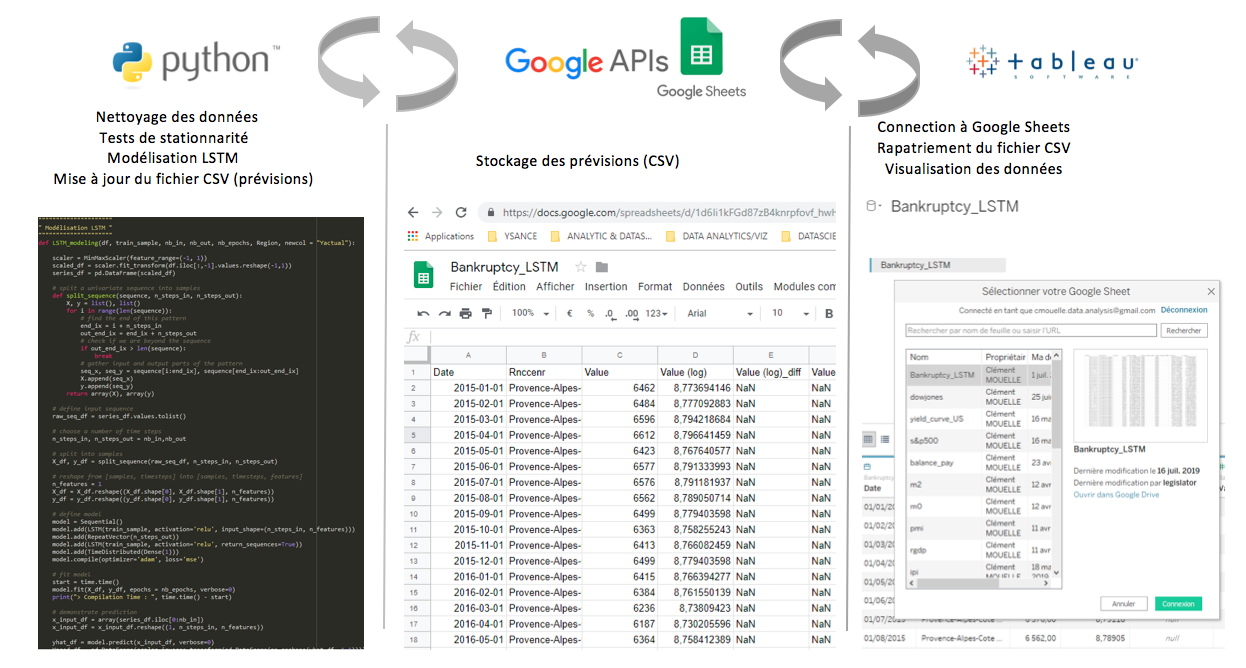
- Analyse de séries temporelles puis modélisation LSTM sous Python
- Export de la base de données contenant les prévisions dans Google Sheets.
- Connexion de Tableau à Google Sheets via un connecteur de données web.
- Visualisation des projections avec toute la batterie d’outils propre à l’Analytics dans Tableau.
Au final, nous obtenons le dashboard ci-dessous où il est possible d’accompagner l’utilisateur dans une interprétation « pas à pas » des résultats.
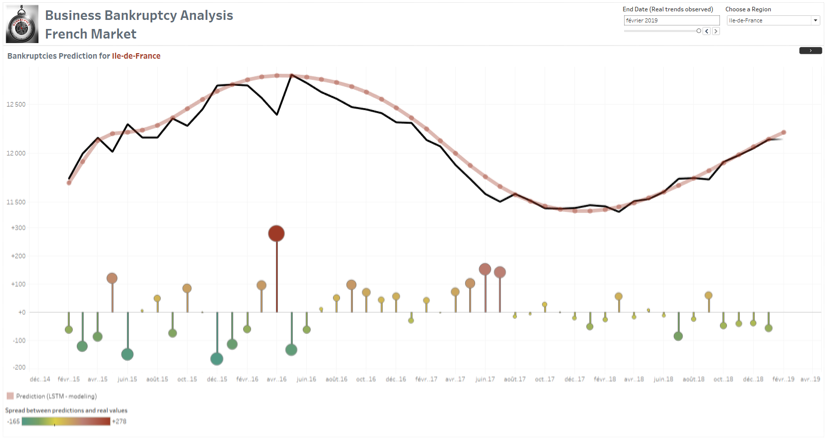
Exemple du « Lollipop chart » qui permet de renforcer les écarts constatés entre les volumes de faillites prévus et réalisées.
Construire une démarche prédictive en self-service BI.
Un autre usage insoupçonné de l’Analytics Augmenté, réside dans sa capacité à construire une démarche prédictive directement au sein d’un logiciel de self-service BI et d’en utiliser les avantages pour accélérer la découverte d’insights.
Illustration et mode d’emploi (ci-après) d’une extension DataRobot au sein de Qlik Sense, de sorte à profiter d’une part de toute la puissance du moteur associatif Qlik, et d’autre part des performances de DataRobot en matière de Machine Learning automatisé.
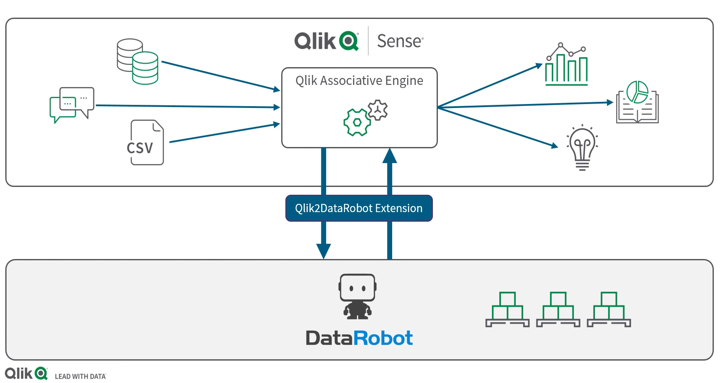
Mode d’emploi.
- Ajouter le bouton hébergeant l’extension DataRobot dans une application Qlik Sense.
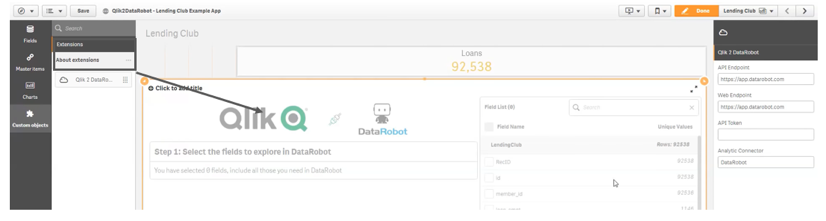
- Sélectionner les champs de données qui seront pris en compte dans l’analyse prédictive et transfert du fichier dans l’interface de développement DataRobot.
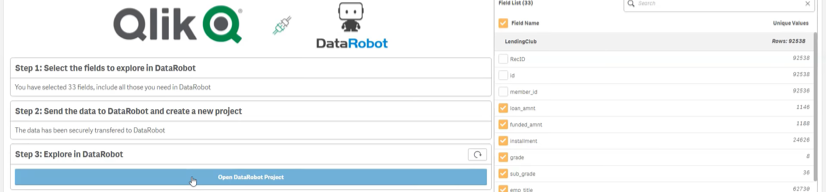
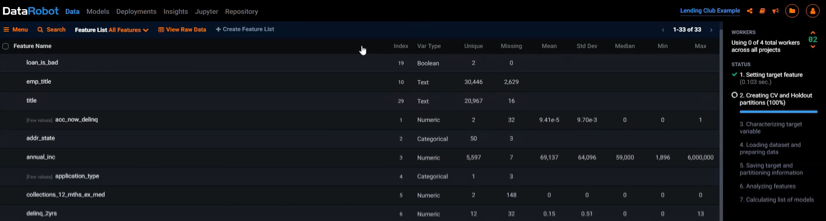
- Travaux d’analyse prédictive dans DataRobot et renvoi des outputs dans Qlik Sense.
- Intégration du nouveau flux de données (prévisions) au sein du script de l’application Qlik Sense, ce qui est un très bon point sur le plan de l’industrialisation de la chaîne de valeur data.
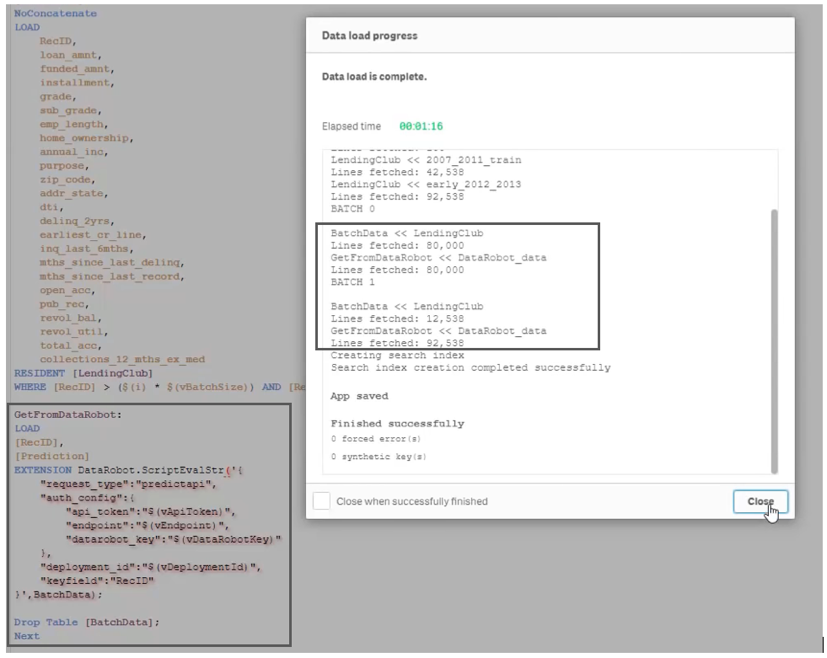
- Interaction automatique entre les parties Analytics et Data Science (recalcul des prévisions et synchronisation instantanée au data model initial selon les critères de filtres utilisés dans la visualisation par l’utilisateur).
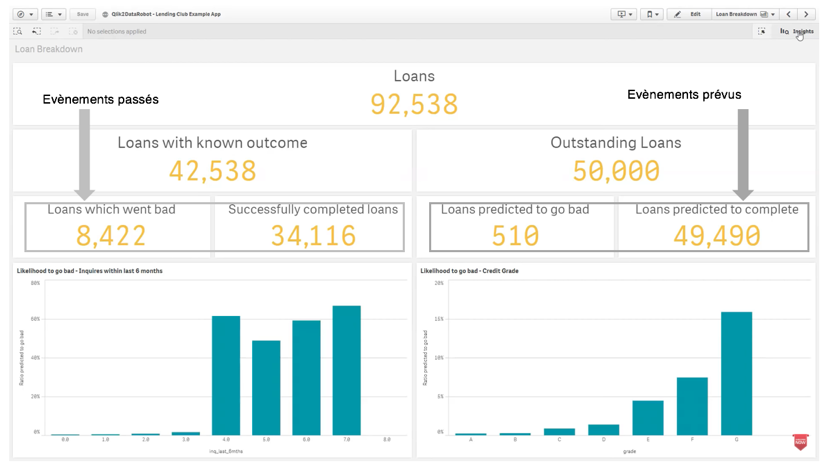
Ainsi, l’Analytics Augmenté peut véritablement booster les projets Data Science tout en profitant d’une découverte d’insights plus efficiente que jamais.
Bien que cette synergie entre ces 2 approches de la donnée n’en soit qu’à ses débuts, l’impact positif qui en résulte est indéniable :
- augmentation de la valeur des données de l’entreprise (innovation),
- augmentation de l’aptitude à la pensée critique avec les algorithmes,
- réduction de l’écart entre les data scientists et les métiers,
- accélération de la prise de décision au sein des organisations.
Cela confirme le fait suivant : posséder des données est une chose, mais savoir les exploiter, les extrapoler puis les restituer en est une autre.

