
Suite à notre premier article abordant le Programme “AWS Open Data”, nous allons nous intéresser au projet Common-Crawl, inclus dans ce programme, et présenter un exemple de code écrit en Python pour voir “comment exploiter le contenu des pages WEB mises à disposition par ce projet”.
L’accès aux données Common-Crawl
Les données du projet Common-Crawl sont mises à disposition dans un bucket S3 mais il est également possible d’y accéder via HTTPS. Le crawler du projet tourne continuellement pendant une semaine tous les mois.
Chaque extraction mensuelle est logée dans un path avec un identifiant caractéristique.
Comme nous pouvons le voir sur la page ci-après : https://commoncrawl.org/the-data/get-started/, la dernière extraction disponible au moment où j’écris cet article est celle de Mars/Avril 2020, et son identifiant est CC-MAIN-2020-16.
Sur le bucket s3, ces données sont accessibles depuis le path :
s3://commoncrawl/crawl-data/CC-MAIN-2020-16
Si l’on souhaite les télécharger via HTTPS, le préfixe de l’URL de chacun des fichiers sera :
https://commoncrawl.s3.amazonaws.com/crawl-data/CC-MAIN-2020-16.
⚠⚠⚠ Ce dernier lien ne permet pas de parcourir les données Common-Crawl depuis un navigateur WEB. Nous allons voir qu’il va nous falloir passer par un fichier d’indirection.
Un autre élément à considérer est l’aspect régional du stockage : les données Common-Crawl sont stockées sur la région us-east-1. Aussi, si nous souhaitons y accéder sur le bucket S3 depuis une instance ec2, il est fortement conseillé de localiser son instance dans la même région afin d’éviter les surcoûts lors du téléchargement des données.
Organisation des données Common-Crawl
Cliquons sur le lien correspondant au dernier crawl :
https://commoncrawl.org/2020/04/march-april-2020-crawl-archive-now-available/
Comme nous l’avons vu dans l’article précédent, les données correspondant aux pages WEB peuvent être dans les fichiers WARC (pages brutes en HTML) ou WET (pages épurées des balises HTML).
Depuis cette dernière page, les données ne sont pas accessibles, mais nous allons pouvoir télécharger les fichiers :
ou
Dans lesquels nous obtiendrons les suffixes à rajouter à
https://commoncrawl.s3.amazonaws.com
afin d’obtenir une url complète qui va nous permettre de télécharger un fichier de données.
zcat wet.paths.gz |head -n 4
crawl-data/CC-MAIN-2020-16/segments/1585370490497.6/wet/CC-MAIN-20200328074047-20200328104047-00000.warc.wet.gz
crawl-data/CC-MAIN-2020-16/segments/1585370490497.6/wet/CC-MAIN-20200328074047-20200328104047-00001.warc.wet.gz
crawl-data/CC-MAIN-2020-16/segments/1585370490497.6/wet/CC-MAIN-20200328074047-20200328104047-00002.warc.wet.gz
crawl-data/CC-MAIN-2020-16/segments/1585370490497.6/wet/CC-MAIN-20200328074047-20200328104047-00003.warc.wet.gz
Et en effet, l’url:
https://commoncrawl.s3.amazonaws.com/crawl-data/CC-MAIN-2020-16/segments/1585370490497.6/wet/CC-MAIN-20200328074047-20200328104047-00000.warc.wet.gz
permet d’accéder à un premier fichier wet.
Pour notre exemple, nous téléchargerons les données en HTTPS ; cela est sans doute moins optimal, mais nous permet de les télécharger gratuitement. Nous travaillerons avec les fichiers WET qui sont beaucoup moins volumineux que les fichiers WARC.
Configuration de l’environnement
Installation de Apache Spark
- Installez un JDK1.8 et définissez la variable d’environnement JAVA_HOME ;
- Ajoutez également $JAVA_HOME/bin dans votre PATH ;
- Téléchargez la dernière archive Spark_2.4 depuis
https://downloads.apache.org/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz - Décompressez-la dans le path de votre choix ; vous l’utiliserez à nouveau pour définir la variable d’environnement SPARK_HOME.
Installation de l’environnement Python
Nous travaillerons avec un environnement virtuel Anaconda de type biopython que nous allons enrichir avec quelques paquets supplémentaires :
$> conda create -n cc-pyspark biopython python=3.7
$> conda activate cc-pyspark
# Ajout des paquets supplémentaires
(cc-pyspark) $> pip install requests
(cc-pyspark) $> pip install warc3-wet
(cc-pyspark) $> pip install lang-id
(cc-pyspark) $> pip install maxminddb-geolite2
(cc-pyspark) $> pip install jupyter
(cc-pyspark) $> pip install plotly
(cc-pyspark) $> pip install pandas
Description des paquets additionnels :
|
paquet |
description |
|
requests |
Pour dialoguer en https |
|
warc3-wet |
Pour parser les fichiers WARC ou WET |
|
lang-id |
Pour identifier la langue d’un texte |
|
maxminddb-geolite2 |
Pour identifier la géolocalisation d’un serveur |
|
jupyter |
Pour travailler avec de Jupyter notebooks |
|
matplotlib + seaborn |
Pour créer des graphiques dans un notebook |
|
pandas |
Dataframes Python exploitables avec plotly |
Sources du projet
Les sources de ce projet peuvent être téléchargées depuis un dépôt git (via la commande “git clone”):
https://github.com/catherineverdiergo/cc-examples
Elles se composent :
- d’un job pyspark qui va créer un dataset pour produire des statistiques par langue et par pays à partir de quelques fichiers WET (wetstatsoncorpus.py) ;
- d’un notebook jupyter utilisant pyspark pour produire quelques statistiques et plotly pour générer des graphiques à partir de ces statistiques (WET stats notebook.ipynb).
Le job wetstatsoncorpus.py
Préalables:
- si vous souhaitez exécuter le programme sous Windows, changez la variable TMP en tête de programme ;
- pour changer le nombre de fichiers à traiter, changez le paramètre nommé num_files ligne 127.
Description du process :
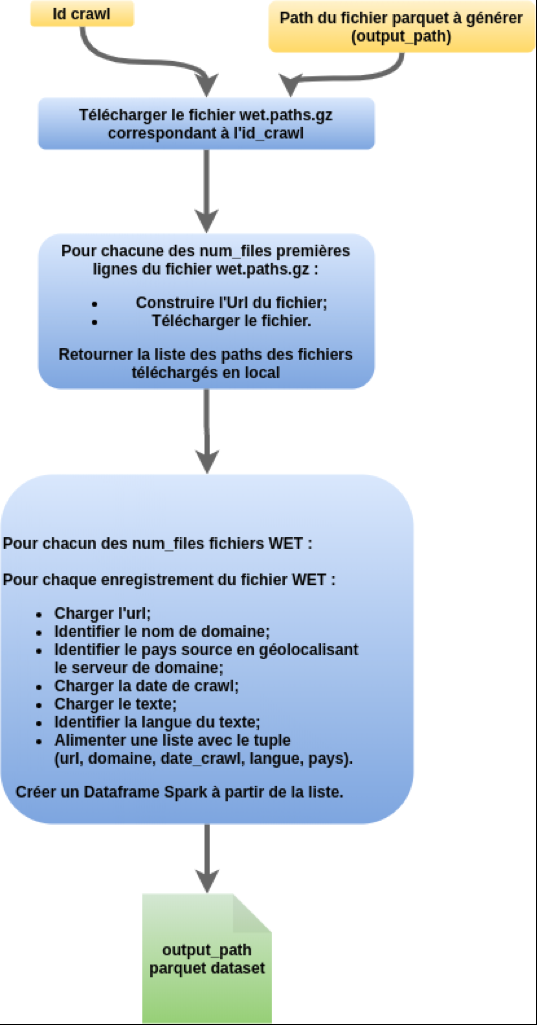
Comment lancer le job ?
(cc-pyspark) $> PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.7-src.zip:$PYTHONPATH \
PYSPARK_DRIVER_PYTHON=`which python` \
PYSPARK_PYTHON=`which python` \
PYSPARK_SUBMIT_ARGS=”local[*] –driver-memory 4g” \
python wetstatsoncorpus.py CC-MAIN-2020-16 for_stats
Note: le job prend un temps non négligeable à cause des tâches d’identification de la langue et du pays. Il est possible d’exploiter directement le dataset résultat (stocké dans le path for_stats).
Le notebook ‘WET stats notebook.ipynb’
Comment lancer jupyter avec Spark ?
PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.7-src.zip:$PYTHONPATH \
PYSPARK_DRIVER_PYTHON=`which python` \
PYSPARK_PYTHON=`which python` \
jupyter notebook
Accéder au notebook depuis le navigateur
Chargez le notebook et depuis le menu, exécutez toutes les cellules.
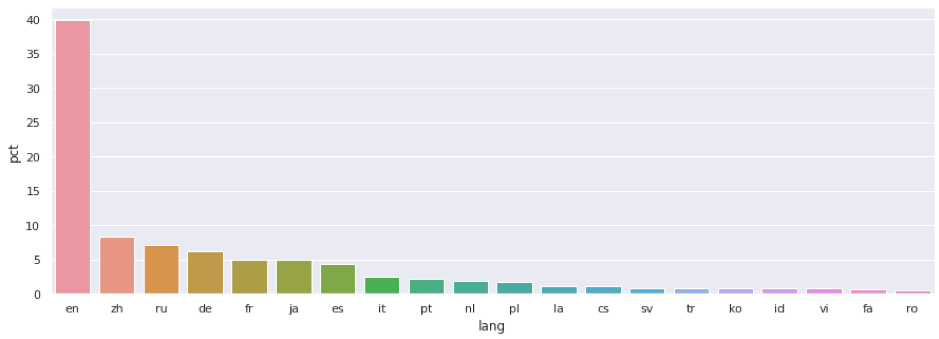
L’objectif est d’obtenir des bar-charts pour connaître sur les caractéristiques les plus courantes des pages (en utilisant la fonction stats du module wetstatsoncorpus).
Par exemple : wetstatsoncorpus.stats(df, « lang », pct=True) retourne un DataFrame Spark donnant le pourcentage de chaque langue dans le corpus et trié en commençant par les langues dont la fréquence est la plus élevée.
Nous pouvons alors facilement présenter avec matplotlib les langues les plus utilisées dans le corpus par un bar-chart ; ce qui donne :
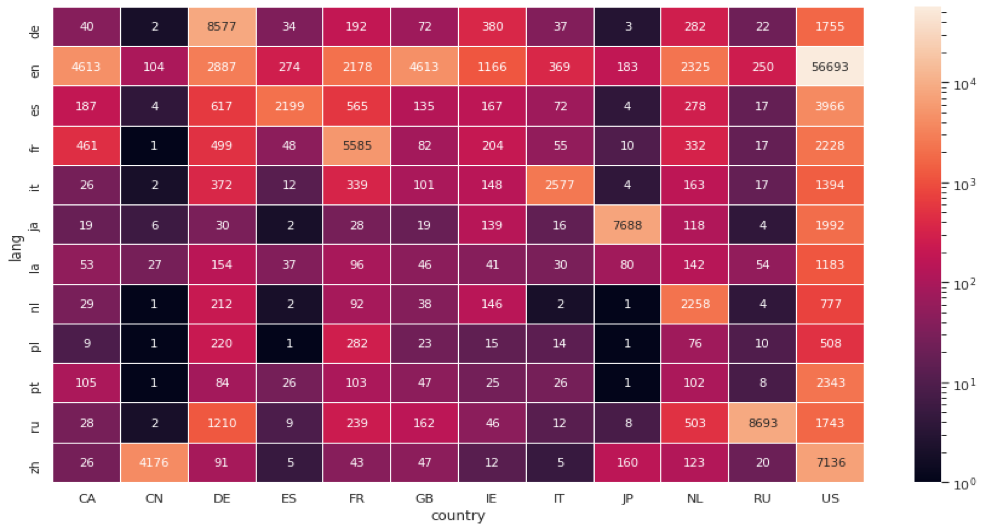
Avec la fonction stats_2_fields du module wetstatsoncorpus, nous pouvons compter le nombre de pages ayant 2 critères communs.
En effet, wetstatsoncorpus.stats_2_fields(df, « country », « lang »), retourne un Dataframe Spark avec le nombre de pages ayant même langue et même pays.
Nous filtrons ensuite ce Dataframe en ne conservant que les 20 pays et 20 langues les plus fréquentes, puis à l’aide de la méthode pivot de pandas, on peut présenter le tableau croisé du nombre de pages par langue et par pays.
Pour l’affichage, nous avons utilisé une échelle logarithmique pour les couleurs à cause d’une très forte prépondérance du couple (US/en).
Conclusion
Nous venons de voir une approche pour exploiter les données Common-Crawl.
De nombreux autres exemples sont disponible ici : https://commoncrawl.org/the-data/examples/
Dans un prochain article, nous verrons comment indexer les textes des pages Common-Crawl à l’aide d’un moteur ElasticSearch afin de construire une base de moteur de recherche.

