
Face à la pandémie du COVID-19, c’est une véritable course aux essais thérapeutiques qui s’est engagée depuis quelques mois avec actuellement un grand nombre de laboratoires pharmaceutiques mobilisés sur le sujet. A ce jour, c’est plus d’une cinquantaine de demandes d’autorisations d’essais cliniques sur le Covid-19 qui ont été soumises rien qu’en France ! Mais qu’est-ce exactement qu’un essai clinique ?
Cet article propose de revenir sur la méthodologie de mise en œuvre d’un essai clinique : comment les mène-t-on ? Comment lire un rapport d’étude et interpréter les résultats ?
Cet article s’adresse à tous parce que les méthodes d’analyse des données de survie sont aujourd’hui appliquées dans de nombreux domaines :
➜ dans le retail (prédiction du churn clients),
➜ en maintenance préventive (prédiction de pannes machines),
➜ en ingénierie système (analyse de modes de défaillances), …
Nous en avons fait la preuve encore récemment chez un de nos clients de la grande distribution : l’application des méthodes d’analyse de survie a permis d’optimiser la fidélisation des clients. Par des techniques R&D, nous avons pu optimiser le nombre de ré-achats et ré-activer des clients qu’on croyait perdus. Cette stratégie du second achat étant connue comme l’un des piliers de la logique de fidélisation durable des clients.
Ainsi, si vous n’êtes pas clinicien, ni même data scientist, ni même salarié du secteur pharmaceutique ou de la santé, cet article est pour vous.
Un essai clinique : c’est quoi ?
Un essai clinique a pour but d’évaluer l’efficacité et/ou la tolérance d’un médicament, d’un traitement ou de toute autre stratégie thérapeutique.
La mise en œuvre d’un essai clinique à fort niveau de preuve doit respecter les critères suivants :
- Comparabilité des résultats : le traitement est-il meilleur qu’un autre médicament (ou meilleur qu’un placebo) ?
- Évaluation de la significativité statistique et clinique : l’amélioration de l’évolution de la pathologie est-elle dûe au seul fait du traitement ou simplement au hasard ?
- Pour ce faire, c’est le critère de jugement (aussi appelé « endpoint ») qui permet d’évaluer l’efficacité du traitement (par exemple, le taux de mortalité, la sévérité des symptômes, la durée de l’hospitalisation, …). Un critère de jugement doit être un critère objectif, simple à évaluer, applicable à tous les patients et valide.
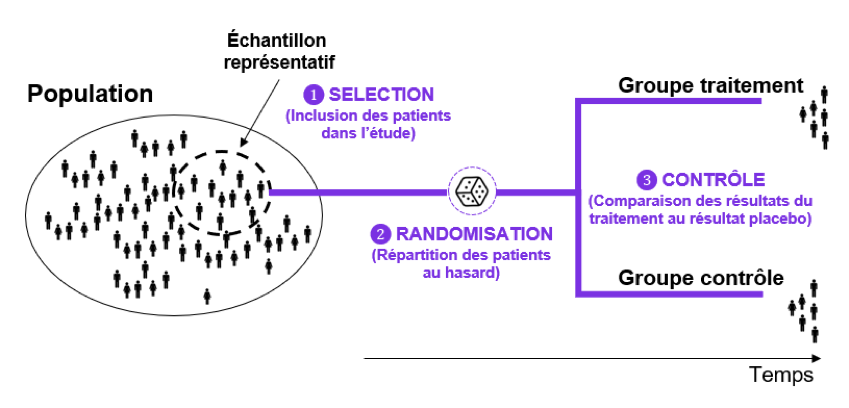
Principe général pour le bon déroulement d’un essai clinique
On cherche à constituer un échantillon représentatif de patients, c’est-à-dire représentatif de la population cible à étudier.
On divise ensuite cet échantillon en 2 groupes de patients :
- Un premier groupe « Traitement » constitué des patients soumis au traitement.
- Un second groupe « Contrôle » constitué des patients qui reçoivent un placebo (ou un autre médicament).
On suit dans le temps les deux groupes et on mesure régulièrement le critère de jugement pour chacun des groupes. En fin d’étude, il est donc possible de comparer la valeur des 2 critères de jugements de chaque groupe et ainsi d’évaluer l’efficacité du traitement.
Pertinence d’un essai clinique
Les meilleurs essais cliniques sont les essais randomisés contrôlés. En effet, il existe de nombreuses possibilités d’erreurs dans la mise en œuvre d’un essai clinique.
- Il y a les erreurs aléatoires qui correspondent à des erreurs de mesures aléatoires, liées aux fluctuations d’échantillonnage. Ces erreurs sont naturelles mais restent à minimiser par des techniques statistiques adaptées.
- Et, il y a les biais d’étude, c’est-à-dire des erreurs systématiques traduisant une erreur de conception de l’étude. Les biais d’étude peuvent perturber fortement l’interprétation des résultats sur l’effet du traitement.
Les essais randomisés contrôlés permettent de minimiser/éliminer ces effets parasites indésirables. On parle d’ailleurs de gold standard (test de référence) pour l’essai randomisé contrôlé parce que ce type d’étude produit le plus haut niveau de preuve d’efficacité d’une nouvelle thérapie ou d’un nouveau traitement.
L’effet d’un traitement peut être :
- lié à une guérison spontanée de la maladie (par exemple, les cas de rhume)
- lié à un effet placebo
- lié à un effet de prise en charge
- associé aux caractéristiques des patients (dans le cas où la comparabilité entre les deux groupes d’étude n’est pas bonne)
- lié à un traitement concomitant (traitement administré en dehors de l’étude)
- lié à une erreur de mesure dans le critère de jugement
➜ Il existe donc un grand nombre de biais d’étude à garder à l’esprit.
Causalité entre effet d’un traitement et la pathologie étudiée
Il existe une causalité entre un traitement administré à des patients et une pathologie étudiée si les deux groupes ne diffèrent que par le traitement et non à cause de facteurs extérieurs. Voilà la raison pour laquelle on utilise un groupe contrôle. Il s’agit d’avoir un comparatif sans le traitement ciblé.
L’urgence de trouver un traitement au COVID-19 est à l’origine d’un grand nombre d’études n’ayant rapporté aucun groupe « Contrôle » (ce sont des études dites séries de cas ou études de cohortes).
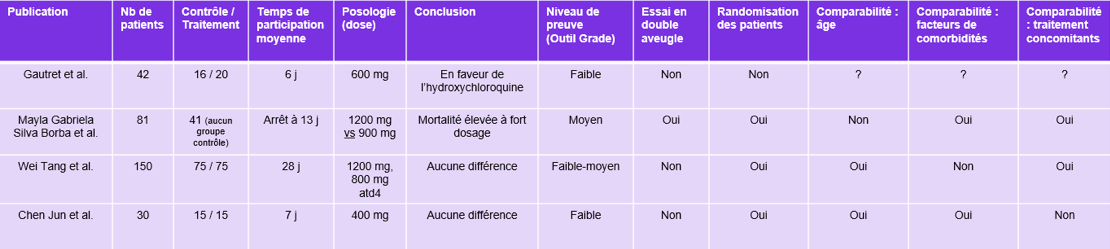
A titre d’exemples, une des études du Professeur Raoult ¹, infectiologue et professeur de microbiologie français à l’Institut hospitalo-universitaire en maladies infectieuses de Marseille présente des biais évidents : cette étude a rapporté une guérison de la majorité des patients entre 7 à 10 jours. Cependant, la plupart des patients étudiés ne présentaient que des symptômes légers, et une moyenne d’âge peu élevée.
Dans tous les cas, le design d’une étude sans groupe comparatif de contrôle ne permet pas de conclure quant à l’efficacité d’un traitement.
La pertinence d’un essai clinique repose également sur la randomisation de l’essai. Il faut affecter de manière aléatoire (tirage au sort) les patients dans les 2 groupes en contrôlant toutes les variables en amont et en s’assurant de l’homogénéité des groupes au début de l’étude. Ainsi, seule l’action de la nouvelle thérapie sera à l’origine des différences obtenues sur les résultats de l’étude.
Le but de la randomisation, c’est d’assurer la meilleure comparabilité entre les deux groupes, en minimisant le biais de sélection des patients.
Quelques précisions sur les principaux biais d’études
On parle de biais de performance et d’attrition pour désigner la différence entre les 2 groupes étudiés en termes de réalisation du traitement, d’adhérence au traitement ou encore de suivi médical.
Les principaux biais d’attrition surviennent lorsque :
- certains patients sont censurés (sortie prématurée de l’étude)
- certains patients changent de traitement au cours de l’étude
- des données sont manquantes dans l’analyse
- les résultats varient en fonction du temps pour certains patients (Par exemple, quelques patients négatifs PCR, ont été testés positifs quelques jours plus tard). Ceci traduit une erreur de mesure avec existence d’un grand nombre de faux négatifs et faux positifs lors des tests PCR.
- de la confusion existe entre deux pathologies (Par exemple, des cas confirmés de patients atteints de COVID-19 pourraient avoir été diagnostiqués atteint COVID-19 à tort. En effet, les premiers symptômes du COVID-19 sont proches de ceux de la grippe. On parle alors de confusion entre grippe et coronavirus).
Gold standard : Essais randomisés contrôlé, en double aveugle
Dans des études en double aveugle, les patients ne connaissent pas le traitement qu’ils reçoivent tandis que les médecins/évaluateurs ne savent pas le traitement qu’ils administrent. Cela permet d’éviter les biais dans les résultats pour cause de modifications des comportements patients/médecins. Par exemple, quelques patients pourraient fausser leur propre jugement sur leurs symptômes tandis que quelques médecins pourraient modifier la qualité des soins ou l’interprétation selon le patient.
Un dernier point d’attention concerne la comparabilité des résultats. La validité d’un essai clinique repose sur la ressemblance entre les populations des deux échantillons de patients. En effet, il s’agit d’ajuster les 2 groupes c’est-à-dire que les 2 groupes de patients échantillonnés doivent être ressemblants à une population cible pour permettre une généralisation des résultats.
Synthèse de cet article au travers de l’évaluation des niveaux de preuve de quelques papiers scientifiques autour du COVID-19.
Sources : Utilisation des plateformes d’archives de prépublications consacrées à la recherche médicale
https://www.ncbi.nlm.nih.gov/pubmed/
Utilisation de l’outil GRADE pour la mise en évidence d’éléments pour les niveaux de preuve
Conclusion
Si vous souhaitez en savoir plus sur le sujet, suivez notre webinaire « Mieux comprendre les essais cliniques et l’analyse de survie à l’heure du COVID-19 » qui aura lieu le mardi 16 juin à 17h.
A ce rendez-vous, nous proposons de partager avec vous quelques retours d’expériences sur les essais cliniques à partir de cas d’études réels :
- Développement d’un traitement en phase II et recherche des meilleures associations de molécules.
- Suivi post-AMM d’un médicament sur le marché et analyse du sur-report d’événements cardiaques indésirables, expliqués par des modèles de machine learning.
__________________________
¹Réf : Hydroxychloroquine and azithromycin as a treatment of COVID-19: results of an open-label non-randomized clinical trial. Gautret P., Lagier JC., Parola P., Hoang VT., Meddeb L., Mailhe M., Doudier B., Courjon J., Giordanengo V., Vieira VE., Dupont HT., Honoré S., Colson P., Chabrière E., La Scola B., Rolain JM., Brouqui P., Raoult D. https://www.medrxiv.org/content/10.1101/2020.03.16.20037135v1

