
Dans notre dernier article, nous avons vu ce qu’est l’autoML, ses avantages/inconvénients et son utilisation dans le cadre d’un projet de machine learning. Nous avons dressé un comparatif des différentes solutions autoML présentes sur le marché pour finir sur un cas pratique développé avec MLBox.
Aujourd’hui nous commençons notre premier article de la série autour de l’utilisation des services autoML cloud. Le but de cette série est de comparer la manière et la facilité d’utilisation de ces services. Cet article sera axé sur la solution de Google : autoML Tables.
Avant d’approfondir avec vous cette solution, une brève présentation de Google Cloud autoML s’impose.
Présentation de Google Cloud autoML
Google Cloud AutoML est une suite de composants pour faire du machine learning (ML) et qui permettent d’entraîner des modèles de machine learning hautement performants et adaptés aux besoins des entreprises.
Le principal avantage de la solution est qu’il est possible de produire des modèles ML avec des connaissances limitées en machine learning, sans avoir à gérer d’infrastructure pour l’entraînement des modèles, ni même la mise en production de ces derniers.
Cloud AutoML permet d’obtenir des résultats rapides et peu coûteux dans des contextes métiers larges : le traitement d’images, de flux vidéos et la vision, le traitement du langage ou encore l’analyse de données structurées.
Il existe différentes familles de composants AutoML, selon le domaine d’application et le cas d’usage étudié :
- Cloud AutoML Vision permet d’entraîner et de déployer des modèles pouvant classifier des images (reconnaissance faciale, reconnaissance de marques ou logos) ou de détecter des objets à l’intérieur des images.
- Cloud AutoML Video Intelligence permet d’entraîner et de déployer des modèles permettant de classifier des segments de vidéos ou de suivre dans un flux vidéo des objets spécifiques.
- Cloud AutoML Natural Language permet d’entraîner et de déployer des modèles permettant de classifier ou d’analyser des documents, d’en extraire les entités (champs « nom du contact », « date de signature ») ou d’en analyser les sentiments et le contenu.
- Cloud AutoML Translation permet d’entraîner et de déployer des modèles permettant de produire des traductions d’une langue à une autre.
- Cloud AutoML Tables permet d’entraîner et de déployer des modèles travaillant sur des données structurées (CSV, txt, Excel) pour résoudre des problèmes de prédictions et de classification.
Le cas d’usage qui va suivre sera traité avec AutoML Tables.
AutoML Tables
Formulation du problème de machine learning
Notre problème est le suivant : nous devons trouver le meilleur modèle qui est capable de reconnaître des chiffres écrit à la main. Ce modèle doit être capable, à partir d’une image représentée par une matrice de 64 valeurs, de prédire la valeur du chiffre représenté.
Il s’agit d’une problématique de prédictions sur des données structurées : nous utiliserons donc AutoML Tables.
Dans le cadre de cette problématique, nous utiliserons en supplément pour notre cas d’usage : une base de stockage des données (Cloud Storage).
Détail de la base de données : Il s’agit du jeu de données public de la librairie python Scikit-learn nommé load_digits. Ce dernier contient la description matricielle des 10 premiers chiffres allant de 0 à 9.
Chaque observation représente une image de taille 8×8 qui est décrite par 64 variables explicatives d’entrée. Ce jeu de données contient 1797 observations au total. (Se reporter à la documentation du jeu de données, pour plus d’informations).
Ces données permettent de résoudre un problème de classification multiple.
Objectif du modèle : il doit être capable de classer un chiffre inconnu et prédire s’il s’agit d’un 0, d’un 1, 3 …
Remarque importante : Votre jeu de données d’entrée doit impérativement contenir au moins 1000 lignes pour être accepter par autoML.
A noter que de nombreux cas d’usage peuvent être résolus par autoML Tables :
- Problématique de détection de fraudes au moyen de paiement
- Prédiction de la valeur de vie clients
- Prédiction du risque de churn clients
- Prédiction de la valeur vie clients de nouveaux clients
Etapes clés de mise en œuvre d’AutoML Tables
Chaque étape réalisée est illustrée par une capture d’écran pour vous permettre de mieux refaire vous-même ce tutoriel. Voici les étapes de la démarche globale :
- Export du jeu de données public en fichier CSV (image 1)
- Import de ce fichier dans l’outil de stockage Google Storage (images de 2 à 5)
- Prototypage du modèle AutoML jusqu’à son déploiement (images de 6 à 16)
- Détails de points clés liés aux résultats du modèle final (prédictions, performances et coûts) (images 17 et 18).
Ici, le but n’est pas de montrer les performances d’autoML Tables avec des données compliquées. Il s’agit de comprendre les concepts de base de ce service.
Début du tutoriel détaillé
Avant d’importer les données dans AutoML Tables, il est de votre responsabilité de les préparer en amont et de comprendre à quelles questions business vous voulez répondre car autoML ne pourra pas le faire à votre place.
1.Chargement et export en fichier CSV du jeu de données
|
import pandas as pd from sklearn.datasets import load_digits data = load_digits() df = pd.DataFrame(data.data) df[‘target’] = data.target data_autoML_tables = « C:\\Users\\UserName\\Documents\\Input\\digits.csv » df.to_csv(data_autoML_tables, index=False)
|
Image 1 : Chargement des données et export en CSV
- Chargement des données dans Cloud Storage
Nous allons importer notre fichier «digits.csv», créé précédemment dans un bucket Cloud Storage. Pour ce faire, allez dans l’écran de navigation « Stockage » puis cliquez sur « Créer un bucket ».
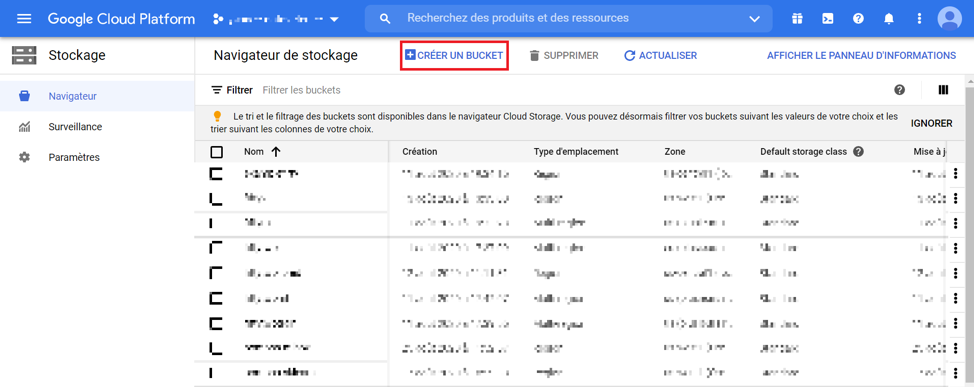
Image 2 : Création d’un bucket
Notons qu’un bucket est un conteneurs d’objets qui doit avoir un nom unique. Vous devez renseigner le type et le lieu d’emplacement (région) du bucket. Il est conseillé de choisir un emplacement qui regroupe l’ensemble des utilisateurs de nos données.
Il existe différentes classes de stockage basées sur la fréquence de consultation des données et permettant d’optimiser les coûts d’infrastructure.
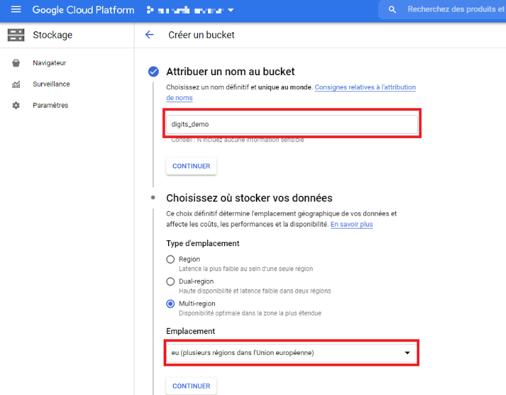
Image 3 : Paramètres de votre bucket
Une fois le bucket créé, nous devons charger le fichier CSV :
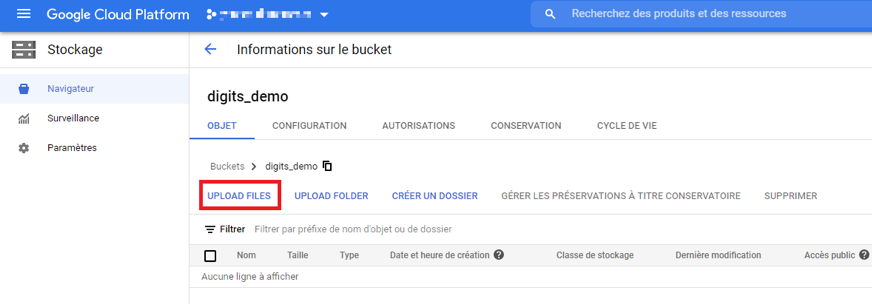
Image 4 : Chargement de vos données structurées
Remarquons que le fichier CSV a effectivement été chargé :
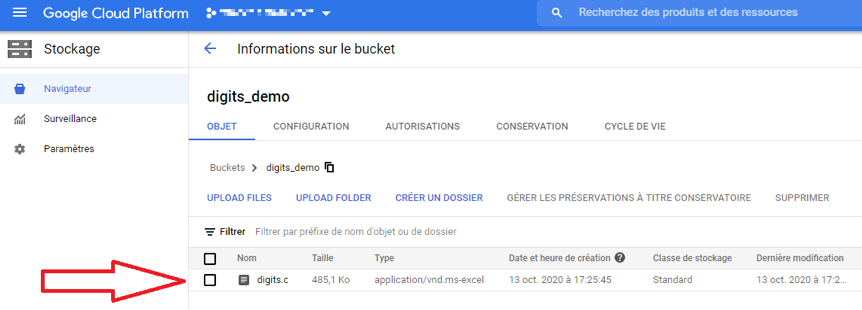 Image 5 : update de vos données
Image 5 : update de vos données
Le chargement de vos données est terminée.
- Création du modèle
L’étape porte sur la création de notre modèle. Pour ce faire, allons tout d’abord dans la partie « Tables » puis créer un nouvel ensemble de données :
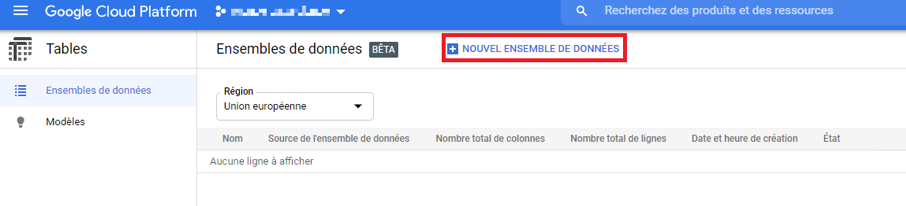 Image 6 : Création de l’ensemble de données
Image 6 : Création de l’ensemble de données
Rappelez-vous que les outils Cloud autoML s’intègrent parfaitement entre eux. Ici dans l’outil autoML Tables nous importons le bucket créé depuis Cloud Storage. Pour ce faire :
- Sélectionner la manière d’importer et choisir celle avec le Cloud Storage.
- Cliquer sur « browse », nous pouvons voir la liste des buckets qui s’affichent.
- Enfin, cliquer sur le bucket « digits_demo » qui a été créé précédemment.
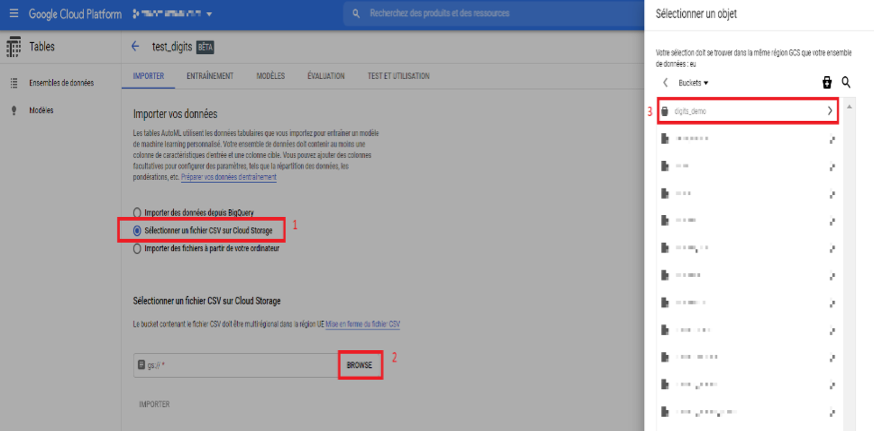 Image 7 : Choix du bucket
Image 7 : Choix du bucket
Une fois le jeu de données importé, nous remarquons qu’autoML a effectué des analyses de base sur chaque variable du jeu de données :
- Typage
- Valeurs manquantes
- Valeurs non valides
AutoML peut se tromper sur ces analyses et cela est normal car personne ne connait mieux votre jeu de données que vous, pas même autoML ! Néanmoins il vous donne la possibilité de les corriger. Par exemple, ici on voit qu’il a affecté à plusieurs colonnes le type Catégorique alors qu’il s’agit exclusivement de colonnes de types Numérique sauf la colonne « target » qui elle est Catégorique.
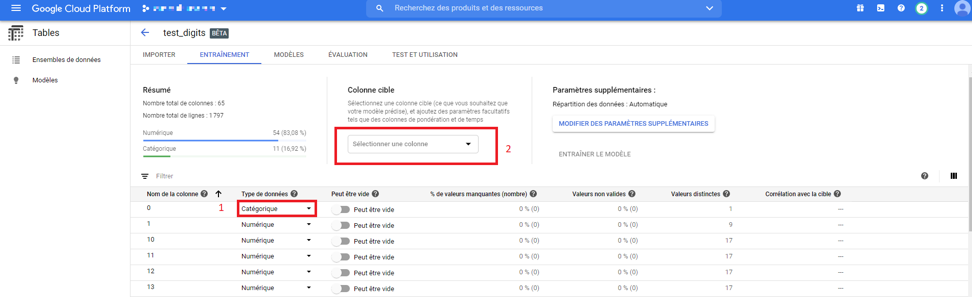 Image 8 : Analytics du jeu de données
Image 8 : Analytics du jeu de données
Cela mènera vers la page que l’on voit ci-dessous, où nous devons spécifier plusieurs informations. Tout d’abord le nom du modèle, ensuite le nombre d’heures maximales que l’entrainement doit durer. Ici le jeu de données possède peu de lignes donc 1H suffira. Notons que le point d’interrogation présent dans le 2eme carré rouge vous spécifie le nombre d’heures à mettre en fonction du nombre de lignes de votre jeu de données. Ensuite, autoML vous laisse le choix de sélectionner les variables que vous voulez pour l’entrainement.
Vous pouvez aussi aller vers les options avancées, il s’agit de choisir la métrique que vous voudriez que le modèle optimise. AutoML vous recommandera les métriques les plus adaptés en fonction de votre problème, s’il s’agit de classification ou de régression. Par exemple s’il s’agit d’une classification comme dans notre cas, il nous proposera les métriques AUC ROC, perte logistique ou la PR AUC sinon pour un problème de régression, ce sera plutôt la RMSE et EAM.
Nous allons maintenant entraîner notre modèle :
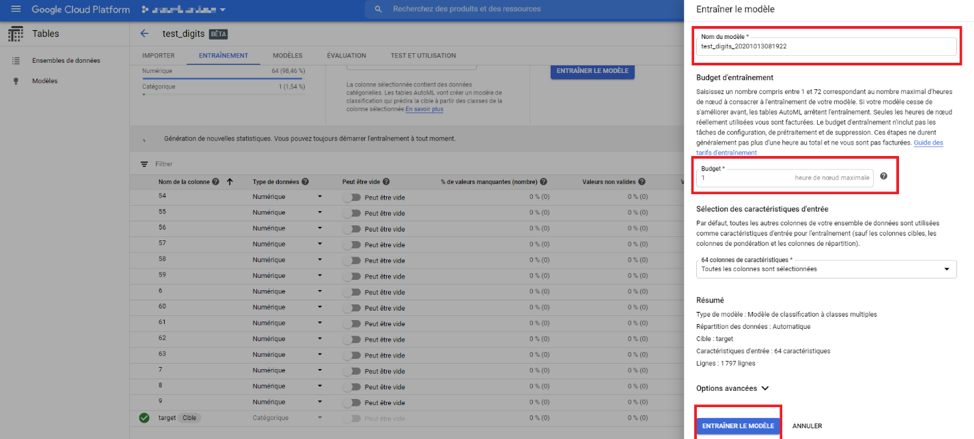 Image 9 : Paramétrage du modèle
Image 9 : Paramétrage du modèle
Une fois l’entrainement lancé, il ne vous restera plus qu’à patienter et attendre le retour de google par une notification mail.
 Image 10 : Entrainement du modèle
Image 10 : Entrainement du modèle
- Résultats du modèle
Après la notification, on constate que l’entraînement est terminé. Notons que la durée entraînement inclut également le choix du modèle à sélectionner en premier lieu, les hyper paramètres à optimiser pour chaque modèle et enfin la comparaison de toutes les combinaisons.
Vous pouvez voir les résultats obtenus par le modèle de manière brève dans l’onglet « Modèles » que nous verrons en détail par la suite dans l’onglet « Evaluation ». Ce qu’il faut retenir dans cette partie est la configuration du modèle obtenu. Le lien « Modèle » représenté par le carré rouge nous donne accès à son architecture. Nous expliquerons les détails en bas de l’article.
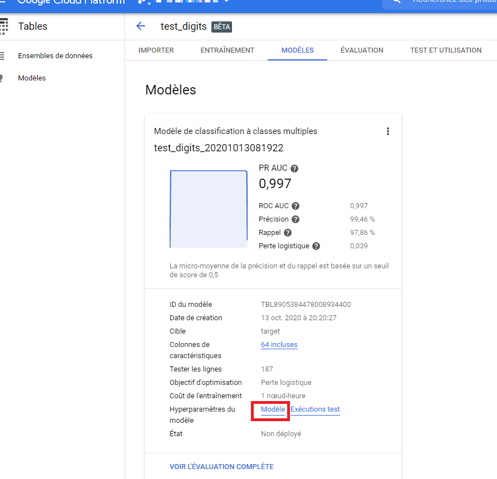 Image 11 : Bref descriptif du résultat
Image 11 : Bref descriptif du résultat
Dans l’onglet « Evaluation », nous avons différentes informations mis à notre disposition pour juger de la qualité de notre modèle (Score F1, Précision, Rappel). Nous pouvons voir que ce dernier a obtenu de très bons résultats avec une aire sous la courbe à 0.977 pour les métriques PR AUC et ROC AUC.
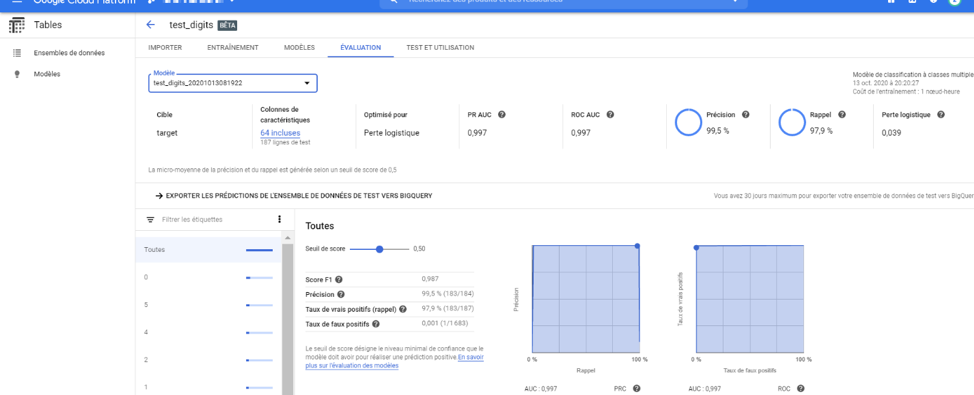 Image 12 : Résultats du modèle
Image 12 : Résultats du modèle
En allant vers le bas de l’onglet « Evaluation », autoML nous montre une matrice de confusion de toutes les classes du jeu de données.
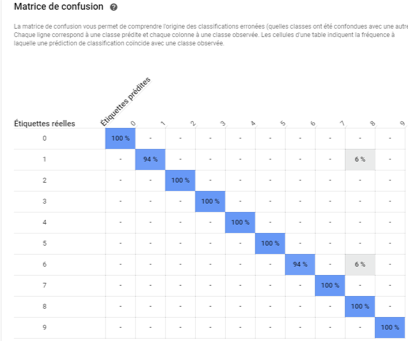 Image 13 : Matrice de confusion
Image 13 : Matrice de confusion
- Prédictions
Enfin dans le dernier onglet «Test et Utilisation». Nous disposons de 3 sous onglets. Le premier est la prédiction par lot ou batch. Nous pouvons importer de plusieurs manières les données que nous souhaitons prédire : soit via BigQuery soit via un Bucket.
 Image 14 : Prédiction en mode batch
Image 14 : Prédiction en mode batch
Dans le sous-onglet «Prédiction en ligne» nous devons déployer le modèle avant de pouvoir faire une prédiction. Ici nous pouvons seulement prédire une ligne à la fois.
 Image 15 : Prédiction en ligne
Image 15 : Prédiction en ligne
Dans le dernier sous-onglet «Exporter le modèle», autoML propose d’exporter le modèle pour pouvoir l’utiliser à votre guise.
 Image 16 : Export du modèle
Image 16 : Export du modèle
Architecture du modèle final
Il faut savoir qu’autoML utilise un nombre limité d’algorithmes de machine learning. Voici la liste des modèles contenus dans autoML :
- Modèle linéaire DNN
- Modèles en arbre de décision à boosting de gradient
- Modèle Adanet AutoEnsemble
- Modèle Adanet
- Modèle en réseau de neurones feedforward
A noter que tous les modèles cités ne sont pas systématiquement testés sur chaque jeu de données. Dans notre cas seul un type de modèles a été utilisé.
AutoML peut donc fournir un ou plusieurs modèles que l’on nomme ensemble de modèle. Dans le cas où autoML génère un ensemble de modèles, ce dernier combine ces modèles pour composer le modèle final. Chacun de ces modèles possède une configuration différente des autres pour obtenir une bonne généralisation. Sur notre exemple, autoML a généré 25 modèles. Nous allons jeter un œil sur un des modèles en particulier.
 Image 17 : Configuration du modèle
Image 17 : Configuration du modèle
Le modèle que l’on voit est un réseau de neurones profond avec une configuration précise. Les 24 autres modèles sont aussi des réseaux de neurones profonds avec des configurations plus ou moins complexes.
Vous pouvez télécharger sous format JSON l’ensemble du modèle obtenu par l’outil.
Explication des prédictions
En tant qu’expert de la data, nous voulons toujours expliquer les prédictions de nos modèles. AutoML met donc à notre disposition deux niveaux d’explication de prédictions :
- Le premier niveau est général :
L’importance des variables sur l’ensemble des prédictions comme nous pouvons le voir dans l’image qui suit :
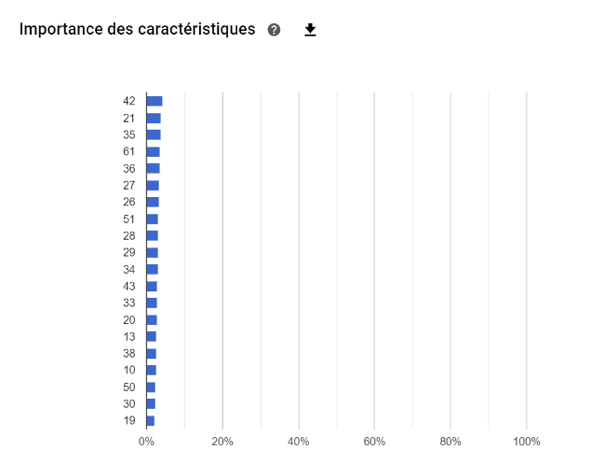 Image 18 : Importance des caractéristiques
Image 18 : Importance des caractéristiques
- Le second niveau est plus précis :
L’importance des variables sur chaque ligne de prédiction, en clair l’impact ou le poids de chaque variable sur chaque prédiction. Cette explication est novatrice et n’est disponible que pour les prédictions en ligne.
Les coûts engendrés par autoML
Il existe un coût pour l’utilisation de l’ensemble de la démarche. Elle est divisée en plusieurs parties :
- L’heure d’entrainement du modèle coute 19.32 $.
- Si vous voulez utiliser le mode de prédiction par lot sachez que cela vous coutera 1.16 $ par heure d’utilisation.
- Enfin, si le mode choisi est celui de la prédiction en ligne, cela vous coutera 0.21 $ par heure d’utilisation + les coûts de déploiement du modèle car ces derniers sont obligatoires pour obtenir des prédictions en ligne. Les coûts de déploiement peuvent varier en fonction de la taille de votre modèle et du nombre d’heures que durera votre déploiement.
Conclusion
AutoML Tables pourrait être critiqué pour : son manque de transparence, la difficulté qu’il y a à comprendre le détail du modèle final retenu, le manque d’explicabilité du modèle retenu. AutoML n’est qu’à ses débuts : n’oublions pas qu’il s’agit d’une version béta toujours en cours d’amélioration.
Néanmoins, notons qu’autoML Tables permet d’obtenir un modèle déployé rapidement, performant, capable de répondre à des problématiques data sans en être un expert. Mais, pour tirer pleinement profit d’autoML Tables, vous devez savoir comment créer un jeu de données prêt à être ingéré en entraînement contenant des indicateurs pertinents pour répondre à votre problématique business (transformation adéquates des variables d’entrée, vérification de la distribution des variables, etc..). Une fois que votre jeu de données d’entrée est prêt à l’emploi, les bénéfices à utiliser autoML sont nombreux.
Pour plus de détails sur les points abordés durant cet article, nous vous invitons à consulter les liens suivants:
- Google Cloud AutoML : https://cloud.google.com/automl
- AutoML Tables Documentation : https://cloud.google.com/automl-tables/docs?hl=en

